현재 글은 컴퓨터 구조와 아키텍처 서적 및 대학에서 들은 강의를 기반으로 한다.
과거 컴퓨터의 발전
- family concept
: 기계의 아키텍처를 구현과 분리. 동일 아키텍처를 이용하되, 다양한 가격대의 부품을 둬서 실제 구현은 다르게 만드는 방식. 아키텍처가 같기 때문에 소프트웨어를 공유해서 사용할 수 있다. - microprogrammed control unit
: control unit을 하드웨어 회로로 구현하는 대신 ROM 상의 프로그램으로 구현하여 family concept을 지원하기 좋음 - 캐시 메모리
: 메모리 계층 상에 캐시를 도입하여 성능 향상 - 파이프라이닝
: fetch & execute 사이클에 병렬성 도입 - multiple processor
등등 여러가지 존재.
RISC(Reduced Instruction Set Computer)
작고 빠른 instruction set을 가지는 모델로, 복잡한 instruction을 간단한 여러개의 instruction으로 변환하여 실행한다. 간단한 명령만을 보유하기 때문에 전반적으로 하드웨어 구조가 단순해지나, 이를 위해 컴파일러가 복잡해지는 특징이 있다.
대략 다음과 같은 특징을 가진다고 한다.
- 많은 범용 레지스터 또는 레지스터 최적화 관련 컴파일러 기술을 가진다.
- 제한된 개수의 간단한 instruction set을 가진다.
- instruction pipeline 최적화를 강조한다.
작업에 드는 시간은 CPI * T * I로 둘 수 있다. 기존의 CISC가 Instruction의 개수를 의미하는 I을 감소시키는데 초점을 두었다면, RISC 머신은 하나의 명령에 소모되는 시간인 CPI와 클럭 당 걸리는 시간인 T를 줄이는 것을 목적으로 한다. 명령이 간단해질수록 여기에 소모되는 시간 및 CPI가 감소하므로, 간단한 명령이 많이 사용된다면 RISC 아키텍처의 도입을 통해 성능 향상을 보일 수 있다.
단, RISC을 도입할 환경이 특수하고 복잡한 명령을 많이 사용해야 하는 경우 복잡한 명령을 다수의 간단한 명령으로 바꿔 실행하므로 시간이 오래 걸린다. 통계적으로 복잡한 명령은 프로그램에서 적게 사용된다는 결과를 기반으로 동작한다.
Instruction Execution Characteristics
- High Level Language
- 프로그래머가 알고리즘을 더 간결하게 표현할 수 있도록 돕는다.
- 컴파일러는 프로그래머 입장에서 알고리즘 표현에 중요하지 않은 영역을 처리한다.
- Execution Sequencing: 실행 순서 지정. control, pipeline 구조를 결정한다.
- Operand used: operand의 타입 및 사용 빈도 등을 통해 메모리 구조, addressing mode 등이 결정된다.
- Operation performed: 프로세서 및 프로세서와 메모리 사이의 상호작용에 의해 수행되는 기능을 결정한다.
- Semantic Gap: 고수준 언어(HLL)와 컴퓨터 아키텍처에서 제공되는 operation 사이의 차이와 연관된다.
이러한 요소들을 고려하여 레지스터의 개수 등 실제 구조를 최적으로 결정하기 위해 다양한 연구들이 수행되었다. 연구들에서는 통계적 결과를 보여주며, 이를 이용하여 instruction과 관련된 다양한 요소를 결정한다. 이때 dynamic measurement 방식을 이용한다.
- static measurement: 각 명령어의 소스 코드 상 등장 횟수를 분석하는 방식
- dynamic measurement: 코드를 실제로 실행하여 각 명령어의 비중을 분석하는 방식.
여러 연구 결과들

고수준 언어에서 자주 등장하는 operation들을 분석한 결과는 위와 같다. 단순 등장 횟수는 ASSIGN이 가장 많지만, machine instruction 수준에서는 LOOP나 CALL의 비중이 상당히 높았다.
메모리 레퍼런스 측면에서는 CALL의 비중이 높았다. 프로시저를 호출할 때는 파라미터나 status 정보를 넘겨줘야 하는데, 이 과정에서 메모리 엑세스가 많이 발생하기 때문이라고 한다.
이러한 결과에 따르면 소스 코드 상의 등장 횟수와 실제 레퍼런스 횟수가 일치하지 않는다는 사실을 알 수 있다. 실제 레퍼런스 횟수를 고려하여 레퍼런스 비율이 높은 operation들을 최적화하는 구조를 가질 필요가 있다.

operand의 경우 상수가 20%, 스칼라 값의 비율이 55%, 배열과 같은 벡터 값의 비율이 25% 정도로 나타났다. 따라서 스칼라 값을 처리하기 적합한 구조를 가질 필요가 있다.

프로시저 콜에 사용되는 argument가 3개 이상 필요한 경우는 최대 7%, 5개 이상 필요한 경우는 최대 3% 정도로 최적화를 고려할 때 고려해야 하는 argument의 개수는 5개 이하면 충분하다.
argument와 local scalar 값들은 둘 다 스택에 저장된다. 이때 해당 값들이 12 워드 크기를 넘을 확률이 전체적으로 6% 이하이므로 최적화에서 고려해야 할 수치도 해당 수준에서 머문다.
다양한 연구에 의해 도출되는 RISC가 가지는 특성은 다음과 같다.
- 많은 레지스터 또는 레지스터 최적화 기술을 통해 operand 최적화를 수행한다. 위 결과에 따르면 고수준 언어에서 ASSIGN과 같은 move statement의 비중이 상당히 높다. 이는 스칼라 참조와 로컬리티 특성에 의한 것으로, 레지스터 참조를 늘리고 메모리 참조를 줄임으로써 성능을 향상시킬 수 있음을 의미한다고 한다.
- 조건부 분기 및 프로시저 호출의 비율이 높으므로 단순하게 파이프라인을 구성하면 비효율적일 수 있다. 따라서 파이프라인을 구성할 때 더 세심한 노력이 필요하다.
Use of Large Register File
- 소프트웨어 측면
- 컴파일러가 레지스터를 할당할 수 있어야 한다.
- 컴파일러 분석을 통해 자주, 오래 사용되는 값들을 레지스터에 할당해야 한다.
- 프로그램에 대한 컴파일러의 상세한 분석 과정이 필요하다.
- 하드웨어 측면
- 더 많은 레지스터를 추가하여, 더 많은 변수가 레지스터에서 실행될 수 있어야 한다.
overlapped register window


프로시저 콜 과정에서 파라미터 전달을 빠르게 수행할 수 있도록 레지스터 윈도우 일부를 겹치도록 구성하는 방식. 파라미터가 중첩된 부분을 통해 바로 전달될 수 있어서 속도가 빨라진다.
레지스터 배정 문제

컴파일러 입장에서 각 변수에게 레지스터를 할당하는 문제는 쉽지 않다. 각 변수가 레지스터에서 동작하는 시간을 표 형태로 나타내면 어떤 변수들은 시간 상의 겹침이 존재하고 또 다른 변수들은 이러한 겹침이 없는데, 겹침이 존재하는 경우 동일한 레지스터에 할당할 수 없게 된다. 이때 해당 변수들을 노드로, 시간 상의 겹침이 있는 경우를 링크로 나타내면 변수에 대한 레지스터에 대한 시간 배정 문제를 그래프 컬러링 문제로 표현할 수 있게 된다.
변수간의 관계를 그래프 형태로 표현했을 때 링크로 연결된 노드는 동일한 색(동일한 레지스터)로 색칠할 수 없다. 이때 기존 그래프 컬러링 이론 중 4색 정리는 평면 상의 지도를 색칠할 때 4개의 색만 존재하면 된다는 사실을 증명했다. 해당 문제는 증명 과정에서 1936가지 경우의 수에 대해 일일히 반례가 없음을 보이는 복잡한 과정을 필요로 한다. 레지스터에 대한 변수 할당 문제는 4색 정리와는 달리 노드 사이에 2차원 평면 이상의 관계를 가지고 있으며, 이를 컴파일러를 통해 계산해야 한다는 점에 있어서 그래프 컬러링 이론 기반 최적화를 달성할 수 없다. 대신 최적에 가깝고 기존 이론들에 비해 훨씬 단순한 near optimal solution을 이용하여 이를 해결한다고 한다.
CISC
CISC 머신은 복잡한 instruction을 많이 보유하는 것이 특징이다. 과거 CISC가 주류를 이뤘던 시절에는 다음과 같은 장점들을 고려했다고 한다.
- 특정 연산과 instruction이 1대 1로 대응되어 해당 연산을 호출하는 역할만 수행하면 되므로 컴파일러가 간단해진다.
- 컴파일러가 간단해짐에 따라 성능이 향상될 것이다.
CISC의 장점 중 하나는 프로그램 코드가 짧아지는 것이다. CISC에서는 하나의 연산이 하나의 instruction에 대응되기 때문에 복잡한 연산이라도 하나의 instruction으로 표현될 수 있다. 코드가 짧아지면 메모리 상에서의 크기도 작아진다.
메모리를 작게 차지하는 경우 메모리 레퍼런스 횟수나 페이지 레퍼런스 횟수가 감소하여 이로 인한 fault가 감소하며, 캐시 내에도 한번에 더 많은 명령을 포함할 수 있는 등의 성능 향상을 기대할 수 있다.
RISC의 특징
CISC에서는 instruction을 복잡하게 만드는 대신 컴파일러를 간단하게 만들고, 프로그램의 크기를 줄여 성능 향상을 기대했다. RISC은 이러한 CISC의 특징과 정반대 위치에 있다. 간단하고 적은 개수의 instruction에 의해 컴파일러의 부하가 커지며, 컴파일러에 의해 연산된 복잡한 instruction들이 긴 코드를 가지므로 메모리 상의 코드 크기도 크다. 그러나 이는 RISC가 추구하는 최적화 방식 자체가 CISC와 다르기 때문이다. RISC의 특징은 다음과 같다.
- one machine instruction per machine cycle
- machine cycle은 2개의 operand을 레지스터에서 가져와 연산하고, 결과를 레지스터에 저장하는 시간을 의미한다. RISC에서 정의되는 instruction들은 모두 한 머신 사이클 안에 종결되므로 더 작은 micro code 단위로 쪼개질 필요가 없다. 따라서 모든 명령은 그대로 hardwired 될 수 있으며, 명령 실행 도중 마이크로 코드를 위한 컨트롤 접근이 거의 존재하지 않아 속도가 상당히 빠르다.
- register to register operations
- RISC 머신은 load & store 아키텍처를 채택한다. 메모리에 대해서는 간단한 load 및 store 동작만 지원하며 모든 연산은 레지스터에서 수행되는데, 이런 구조는 instruction set과 control unit을 단순하게 만드는데 도움을 준다.
- Simple Addressing mode
- RISC 아키텍처에서 주소는 하나의 레지스터와 하나의 상수를 조합하여 일관적으로 사용할 수 있다.
- simple instruction formats
- 하나 혹은 몇 개에 불과한 포맷을 이용한다.
- instruction의 길이는 고정되어 있거나, 워드의 배수로 나타난다.
- opcode의 디코딩 및 register operand 접근이 동시에 수행될 수 있다.

단일 연산 수준에서 RISC의 성능은 CISC에 비해 떨어질 수 있다. Load & Store 방식을 채택하는 특성 상 메모리에서 데이터를 읽고 쓰는 과정이 명시적으로 구분되어 있으므로 CISC의 동일한 연산에 비해 instruction의 개수도 많고, 코드의 크기도 크다.

반면 instruction의 개수가 증가하는 경우, 특히 값들이 한번 load되서 계속 사용될 수 있는 상황에서는 각 instruction마다 data fetch 작업이 필요한 memory to memory 방식과는 달리 가져온 값을 활용하여 사용할 수 있으므로 실행 속도 및 코드의 길이가 크게 감소하는 효과가 있다.
파이프라이닝
RISC의 특징 중 하나는 파이프라이닝에 최적화되었다는 것이다. 파이프라이닝에 따른 성능 향상을 보자.
파이프라이닝 X
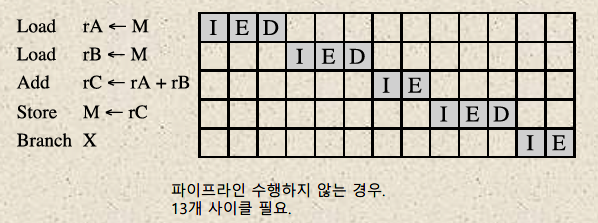
파이프라이닝을 수행하지 않는 경우다. 단순히 순차적으로 실행되며, 13 사이클이 요구된다.
2 스테이지 파이프라이닝

I / ED로 스테이지를 나눈 상태이다. 총 10 사이클이 사용되었다. Load rB <-M 과정에서는 1 사이클을 대기하는 모습을 볼 수 있다. 현재는 data / instruction에 대한 캐시가 동일한 상황으로, 1 사이클을 대기하지 않으면 메모리 접근에 있어서 conflict가 발생하기 때문에 대기했다고 한다. Branch 뒤에는 delayed branch을 위한 NOOP이 삽입되었는데, 컴파일러 최적화 과정에서 해당 값 위치로 Store M <- rC가 이동하면 1사이클 더 이득을 볼 수 있다.
3 스테이지 파이프라이닝

conflict을 없애기 위해 data / instruction에 대한 캐시를 분리한 경우의 구조다. 캐시에서 데이터 및 명령을 가져올 수 있기 때문에 메모리 때문에 발생하는 resource conflict가 사라진다. rA, rB에 데이터를 가져와야 Add을 수행할 수 있으므로 Add 이전에 NOOP가 삽입된 모습을 볼 수 있다. 여기서도 delayed branch을 위한 NOOP이 branch 뒤에 삽입되었다.
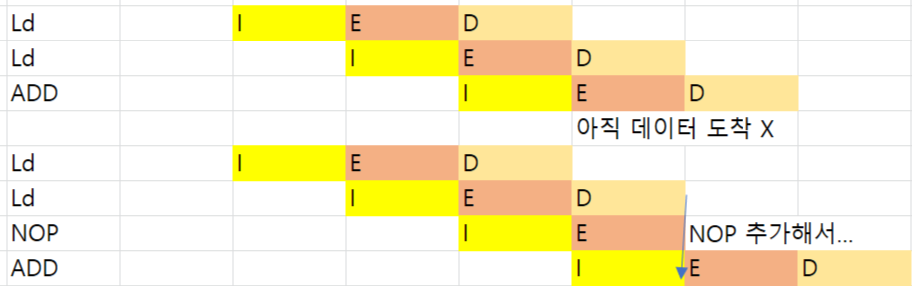
NOP이 삽입된 이유를 구체적으로 나타내면 위와 같다. Ld 작업은 D stage가 종료될 때 완료된다. 따라서 위의 경우 ADD을 하려고 해도 rB에 데이터가 아직 도착하지 않은 상황이라 연산할 수 없다. 이를 위해 NOP으로 한 타임을 대기한다.
4 스테이지 파이프라이닝
Execution 과정은 다른 과정에 비해 시간이 오래 걸린다. 따라서 해당 과정을 둘로 쪼개 각 스테이지에 요구되는 시간을 줄이는 최적화를 고려할 수 있을 것이다.

전체적인 사이클의 수가 증가한 것 같지만, 한 사이클 당 걸리는 시간도 같이 감소했으므로 전반적인 성능은 향상된다.
파이프라인 최적화
- delayed branch
- 브랜치 뒤에 브랜치와 상관 없이 실행되는 코드를 삽입하여 branch에 의한 사이클 낭비를 줄이는 방식.
- delay slot 위치에 브랜치와 무관한 instruction을 삽입한다.
- delayed load
- load 때문에 유휴 상태가 되는 위치(load 뒤의 NOOP)에 해당 load와 관련 없이 동작하는 코드를 삽입하여 실행하는 방식. 사이클 낭비를 막을 수 있어 효율이 증가한다.
- Loop Unrolling
- 루프의 본문 부분을 여러번 반복함으로써 루프를 펴는 방식.
- conditional branch에서 발생하는 오버헤드를 줄이기 위해 루프의 iter 횟수를 감소시킨다.
- 레지스터, 데이터 및 TLB의 로컬리티가 증가하는 효과가 있다.
- 더 많이 편다고 좋은 것은 아니다. 특히 캐시에 한번에 들어갈 수 있는 크기가 적당하다.


SPARC(Scaleable Processor ARChitecture)
RISC 아키텍처의 시초인 버클리 RISC, 스탠포드 MIPS, IBM 801 중 버클리 RISC을 따르는 아키텍처. overlapped register window 등의 register organization 및 instruction set을 가진다.



'CS > 컴퓨터구조' 카테고리의 다른 글
| [컴퓨터구조] ILP & superscalar processor(2) (0) | 2022.11.28 |
|---|---|
| [컴퓨터구조] ILP & superscalar processor(1) (0) | 2022.11.23 |
| [컴퓨터구조] 프로세서 구조 및 기능(1) (0) | 2022.11.17 |
| [컴퓨터구조] Instruction set(2) (0) | 2022.11.09 |
| [컴퓨터구조] Instruction set(1) (1) | 2022.11.07 |



