현재 글은 컴퓨터 구조와 아키텍처 서적과 학교 교안을 기반으로 한다.
프로세서가 하는 일
- Fetch Instruction: 메모리(캐시, 레지스터 포함)에서 instruction을 읽는다.
- Interpret Instruction: 해당 Instruction이 수행해야 하는 작업을 알기 위해 decode 한다.
- Fetch Data: I/O 또는 메모리로부터 필요한 데이터를 읽어온다.
- Process Data: 데이터에 대해 arithmetic / logical 연산을 수행한다.
- Write Data: 연산 결과를 메모리 또는 I/O 모듈에 쓴다.
이러한 동작들이 제대로 실행될 수 있도록 프로세스가 구현되어야 한다.

레지스터 구조
프로세서 내부에는 메모리 계층 상 메인 메모리 및 캐시보다 상위에 위치하는 레지스터가 존재한다. 레지스터는 크게 두 종류의 역할을 수행한다.
- User-Visible Register : 사용자가 접근할 수 있는(볼 수 있는) 레지스터. 최적화 등의 용도로 사용된다.
- Control and Status Register: 사용자가 볼 수 없는 레지스터. 내부 설정, 상태 관리 등에 사용된다.
User-Visible Register
사용자가 접근할 수 있는 레지스터. 메모리 접근을 줄이기 위한 최적화 과정 등에 사용될 수 있다.
- General purpose: 프로그래머에 의해 어떤 용도로든 사용될 수 있는 영역
- Data: 데이터 저장 용도로만 사용되는 레지스터. operand 주소 계산에 사용될 수 없음
- Address: 주소 지정에 사용되는 레지스터로 모든 주소에 대해 범용적으로 사용될 수도 있고, 특정한 주소 모드에만 사용될 수도 있다.
- Condition codes: 연산 결과 발생한 조건 등을 저장하는 코드. 각 비트는 프로세서 연산에 의해 설정되며, RISC-V는 X
Condition Code의 장단점
- 장점
- 컨디션 코드는 일반적인 수학 연산이나 데이터 이동 instruction에 의해 설정돼서, COMPARE / TEST instruction이 필요한 경우를 감소시켜준다.
- 컨디션 코드가 없으면 test-and-branch와 같이 값에 대한 테스트 및 분기를 동시에 수행해야 하는데, 컨디션 코드가 있음으로써 이를 간단하게 처리할 수 있다.
- 한번 비교한 값을 이용, 여러 번 브랜치를 수행할 수 있다. ( 일종의 switch case처럼 동작. )
- CMP 이후 gt, ge, e, le, lt 모두 수행 가능.
- 서브루틴 호출에 의해 레지스터 정보가 변경되는 경우 잠시 스택에 저장해둘 수 있다.
- 단점
- 컨디션 코드가 복잡함을 가중하여 하드웨어 및 소프트웨어를 복잡하게 만든다.
- 일반적인 규칙성을 가지지 않는다. main data path에 없어서 추가적인 하드웨어가 필요하다.
- 16비트 시스템에서 32비트 시스템으로 변경된다고 조건이 1비트 추가된다던지 하는 것은 아님. 일관성이 없어서 기기에 맞게 새롭게 구현해야 할 수 있음.
- bit checking, loop control, atomic semaphore 등 특별한 상황에서 상태 조건을 바꾸지 않겠다는 의미를 가지는 추가적인 condition code가 요구됨.
- branch의 dependency로 인해 파이프라인 구현의 효율이 낮아짐.
Control & Status Registers
- Program Counter(PC): 다음에 실행할 instruction의 주소를 저장한다.
- Instruction Register(IR): fetch로 가져온 Instruction을 저장한다.
- Memory Address Register(MAR): 메모리 주소를 저장한다. 메모리 버스에 바로 연결된다.
- Memory Buffer Register(MBR): 메모리에 쓰거나, 최근에 읽어온 워드를 저장한다.
PSW(Program Status Word)
시스템의 순간적인 상태 정보를 담고 있는 워드.
- sign: 연산 결과가 sign인 경우
- zero: 연산 결과가 0인 경우
- carry: 연산 결과 상위 비트가 넘어가는 경우(multi-word 단위 연산)
- equal: 비교한 결과가 동일한 경우
- overflow: 수학적 연산 결과 오버플로우가 발생한 경우
- interrupt enable/disable: 인터럽트 허용 여부
- supervisor: 프로세서가 관리자 / 유저 모드 중 어떤 모드에서 실행되고 있는지 표현.
- ex) privileged instruction...

파이프라인 전략

공장의 어셈블리 라인처럼, 각 위치에서 들어온 데이터에 대해 처리하고 다음 위치에게 해당 데이터를 전달하는 방식. 기존 스테이지에서 처리된 output은 다음 스테이지의 input이 되어 이어진다.
instruction에서 파이프라인 개념을 이용하려면, instruction 자체를 여러 개의 스테이지로 쪼개야 한다.

가장 간단하게 쪼개면 2단계로 나눌 수 있다.
- Fetch: instruction 등을 가져와서 버퍼에 저장한다.
- Execute: 가져온 instruction을 실행한다.
Fetch 단계에서는 메모리에 저장된 instruction 정보를 가져와서 임시 버퍼에 저장한다. 해당 정보는 Execute 단계로 넘어가서 동작을 수행하는 데 사용된다. 두 동작이 독립적으로 분리되어 있는 경우 연달아 들어오는 프로그램들을 동시에 처리할 수 있게 된다. A와 B라는 프로그램을 실행하는 상황을 가정해보자. 각 스테이지에서 동시에 여러 개의 프로그램을 처리하는 것 자체는 안되므로(메모리에서 A와 B 관련 정보를 동시에 가져와서 instruction을 추출하는 작업 같은 것은 X) A 먼저 Fetch을 한다. 이후 A가 Execute 단계로 가면, Fetch 단계는 현재 비어 있으므로 B가 들어올 수 있다. 이 경우 메모리 사이클을 놀리지 않아 A, B를 연속으로 실행할 수 있어 실행 속도가 짧아진다.
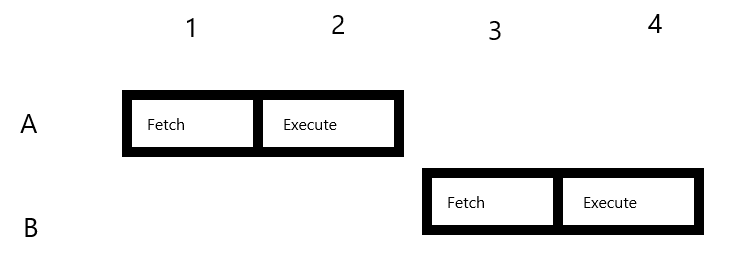

파이프라이닝의 핵심은 한순간에 각 스테이지가 독립되어 있다는 것이다. 모든 스테이지가 독립되어 있어 한 사이클에 스테이지 개수만큼의 instruction을 이론적으로 실행할 수 있으므로 속도 향상이 발생한다.
기존 K 스테이지를 기준으로 N개의 instruction을 실행하는 경우, serial 한 실행 방식은 N * K의 시간이 든다. 반면 파이프라인을 적용하면 한 번에 K개의 명령을 실행할 수 있으므로 K + (N - 1) 번의 실행으로 끝낼 수 있다. 이때 N이 무한대로 간다면 파이프라인 기법의 속도 향상은 스테이지의 개수 K에 비례한다.



물론 실제 상황에서 다음과 같은 속도 향상을 가지는 것은 어렵다. 다음과 같은 문제들이 존재하기 때문이다.
- fetch에 드는 시간보다 execute에 드는 시간이 훨씬 길다. 클럭의 길이는 가장 긴 작업을 기준으로 설정된다.
- conditional branch instruction이 있는 경우, 다음 실행할 instruction이 무엇인지 확정할 수 없어 이를 확실하게 알 수 있을 때까지 instruction 실행을 멈춰야 한다. ( 나중에 branch prediction / speculate 등을 이용하여 처리 )
그렇긴 하지만, 실제로 속도 향상이 있다는 사실만은 확실하다. 따라서 현대 컴퓨터들은 파이프라인의 스테이지 개수를 늘려 파이프라이닝의 효율을 높인다. 파이프라인의 스테이지 개수를 늘리는 것은 단일 작업을 잘게 자르는 행위이므로, 클럭의 길이를 짧게 만드는 효과도 존재한다.
착각할 수 있는 부분이 있다. N개의 instruction 및 K개의 스테이지를 고려했을 때 모든 instruction을 끝내는데 걸리는 사이클 수는 K + N - 1이다. 이때 숫자만 생각한다면 스테이지의 개수가 감소하면 사이클의 수도 감소하는 상황이 발생한다. 그런데, 여기서 고려하지 않은 점은 스테이지 개수에 따라 하나의 사이클에 드는 시간도 1/K 비율로 감소한다는 사실이다. 따라서 단순 사이클이 아니라 걸리는 시간을 따지면 스테이지의 개수가 증가하는 편이 시간이 더 짧게 걸린다.
파이프라인에 대해 일반적으로 다음과 같은 스테이지를 고려한다.

- Fetch Instruction(FI) : 실행될 것으로 생각되는 instruction을 가져와서 버퍼에 집어넣는다.
- Decode Instruction(DI): opcode와 operand 정보를 결정한다.
- Calculate Operands(CO): operand에 대한 effective address을 계산한다. (다양한 주소 지정법들 고려)
- Fetch Operands(FO): operand들을 메모리로부터 읽어온다.(레지스터는 X)
- Execute Instruction(EI): 지정된 동작을 수행한다.
- Write Operand(WO): 결과를 메모리 상에 저장한다.

파이프라인의 각 스테이지에서 다음 스테이지로 정보를 전달하기 위해서는 잠깐 해당 정보를 저장할 버퍼 공간이 필요하다. 실제로 각 파이프라인 스테이지 사이에는 Latch라는 속도가 매우 빠른 임시 버퍼 저장공간이 존재하여, 해당 위치에 잠깐 정보를 저장해둔다고 한다.

파이프라인은 위와 같이 동작한다. 각 스테이지에서 처리된 데이터는 다음 스테이지로 이동하여 순서대로 처리된다. 스테이지마다 하나의 데이터를 처리할 수 있으므로 동시에 여러 개의 instruction이 실행될 수 있다.

그러나 앞서 언급한 대로 모든 상황에서 파이프라이닝의 효과를 볼 수 있는 것은 아니다. 위 그림에서는 Instruction 3의 결과에 따라 conditional branch가 발생하는 상황을 보여주고 있다. 브랜치에 의해 점프를 할지, 하지 않을지는 Instruction 3이 수행되고 나서(Execution Instruction) 알 수 있다. 따라서 Instruction 3에 의해 Instruction 15로의 점프가 수행되어 뒤에 실행되고 있던 Instruction 4 ~ 7의 정보가 의미를 잃음에 따라 버려진다. 이는 conditional branch에 따라 어떤 명령도 완료되지 않는 사이클이 발생하는 branch penalty에 해당한다.
파이프라인 해저드(Pipeline Hazard)
파이프라인을 이용하면 이론적으로 최대 스테이지 개수에 해당하는 K배의 속도 향상을 기대할 수 있음을 보였다. 그러나 실제로는 여러 가지 의존성 문제로 인해 파이프라인을 방해하여 계속 실행할 수 없게 만듦으로써 파이프라인 중간에 멈춤(stall)을 유도하는 문제점들이 있다. 이를 파이프라인 해저드라고 부른다.
파이프라인 해저드는 크게 3가지 분류로 나뉜다.
- Resource Hazard: 자원(메모리, I/O 장치 등)에 동시에 접근
- Data Hazard: 데이터(특정 변수 값 등)에 동시에 접근
- Control Hazard: 분기 등에 의해 발생
리소스 해저드(Resource Hazard)
두 instruction이 이미 파이프라인 상에 있는데, 동일한 리소스(하드웨어 자원)를 요구하는 경우에 발생하는 해저드.

위 그림처럼 5개의 스테이지로 구성된 파이프라인을 가정하자. Fetch Instruction(FI) 및 Fetch Operand(FO) 작업은 둘 다 메모리 참조를 필요로 한다. 이때 두 과정이 동일 사이클에 발생하는 시점이 존재할 수 있는데, 메모리는 한 번에 하나의 데이터만 읽거나 쓸 수 있으므로 둘 중 하나의 작업은 뒤로 밀려야 한다.

이 그림에서는 I3의 FI 시점이 리소스 해저드를 피하기 위해 한 사이클 동안 멈춤으로써 동일 사이클에 위치하는 것을 막는 모습을 볼 수 있다. 어떻게 보면 가장 단순하고 근본적인 해결책이다.
리소스 해저드를 피하기 위한 대책으로 하드웨어를 추가하는 방법도 있다. 만약 Instruction 및 Data들이 L1 캐시에서 히트할 수 있는 상황이라면 메모리 접근을 피할 수 있으므로 대기 없이 그대로 파이프라인을 진행할 수 있었을 것이다.
데이터 해저드(Data Hazard)
두 instruction이 파이프라인 상에서 실행중일 때 데이터의 종속성 때문에 발생하는 문제로, 크게 3가지로 나뉜다.
- RAW(Read After Write): 이전 명령의 쓰기 동작이 끝나기 전에 다음 명령의 읽기가 발생하는 경우
- WAR(Write After Read): 이전 명령이 읽기 전에 나중 명령이 내용을 먼저 쓰는 경우
- WAW(Write After Write): 나중에 실행되어야 하는 명령이 이전에 실행되는 연산보다 먼저 값을 쓰는 경우
RAR은 없다. 당연한게, 읽기는 데이터를 바꾸지 않기 때문에 먼저 읽든 나중에 읽든 동일하기 때문이다. 또한 위 제시한 종류 중 WAR 및 WAW의 경우 실제로 의존성이 존재하는 경우가 아니므로 하드웨어적 추가나 개선으로 문제를 해결할 수 있다고 한다.
RAW(Read After Write, True dependency)

RAW은 이전 명령의 쓰기 동작이 끝나기 전에 다음 명령의 읽기 동작이 수행되어 발생하는 문제를 의미한다. 예를 들어 위 그림에서 EAX에는 10, EBX에는 5, ECX에는 20이라는 값이 들어있다고 생각해보자. 시간을 따로 대기하지 않는다면 I1에 대한 EI, WO와 I2에 대한 FO, EI는 각각 동일한 클럭에서 실행된다. 이 경우 I2는 ADD 연산이 반영된 EAX의 값(15)이 아닌 기존의 값(10)을 기준으로 연산을 진행하기 때문에 완전히 다른 결과가 나타나게 된다.
| 사이클 | I1 | I2 |
| 4 | EAX + EBX 연산 수행(EI) (15 = 10 + 5) |
Operand 값 가져오기(FO) (A = 10, C = 20) |
| 5 | EAX 주소 위치에 15 값 쓰기(WO) (EAX <- 15) |
ECX - EAX 연산 수행(EI) (10 = 20 - 10) |
위 그림에서는 이런 문제를 I2의 실행을 대기함으로써 해결했다. 보다시피 C = C - A라는 연산은 A = A + B라는 연산에 의존성을 가진다. 이처럼 RAW은 instruction 사이에 실제로 dependency가 존재하는 상황이라 해결하기 어렵다.
WAR(Write After Read, Antidependency)
WAR은 이전 명령이 데이터를 읽기 전에 다음 명령의 쓰기가 수행되는 경우를 의미한다.

위 표에서는 나중에 실행된 ADD 명령에서 R2 값을 먼저 변경함으로써 이전 명령에 영향을 주는 모습을 보여준다. 이때 두 연산 자체에는 연관성이 없기 때문에 하드웨어를 추가하여 첫 명령에서 R2 대신 R5의 값을 읽어오게 하거나, 영향을 받는 기간만큼 대기시키면 문제가 발생하지 않는다.
WAW(Write After Write, Output dependency)
WAW은 이전 명령이 데이터를 쓰기 전에 다음 명령의 쓰기가 수행되는 경우를 의미한다.

위 명령을 기준으로 생각해보자. 원래대로라면 R1의 값을 R2가 가리키는 주소에 해당하는 위치에 쓴 후 R1에 R2+R3 결과를 저장하게 된다. 그러나 WAW가 발생하면 ADD 연산이 먼저 종료되어 기존 R1에 저장되어 있던 워드가 덧셈 연산에 의한 것으로 바뀌고, R2가 가리키는 위치에는 해당 연산 결과를 저장하게 된다. 예를 들어 기존 R1의 값이 100을 0번지에 써줘야 하는데, ADD 연산에 의해 R1에 있는 값이 15로 변경되어 0번지에 15를 쓰게 된 상황이다.
이 경우도 마찬가지로 하드웨어를 추가하여 문제를 간단하게 해결할 수 있다. ADD R1,R2,R3을 ADD R4,R5,R3 과 같이 변경하면 WAR, WAW 둘 다 발생하지 않는다.
Data Dependency 해결법
- Hardware Interlocking(lock): 원하는 순서대로 데이터가 처리될 수 있도록 락을 걸어서 대기(stall)하게 만든다.
- Internal Forwarding: 연산 되는 중간 값을 다른 위치에 저장하지 말고 곧바로 다음 단계에 전달될 수 있도록 내부적인 경로를 둬서 처리하는 방식이다.
- Delayed Load: 컴파일러 수준에서 NOP(일정 시간 대기)을 추가하여 기다리게 만드는 방식이다. 추가된 대기 기간은 컴파일러의 최적화 과정에 따라 제거될 수 있다. 컴파일 타임이 조금 길어지는 대신 실행 시간이 빨라질 수 있으며, 하드웨어를 추가하지 않아도 된다는 장점이 있다.
- Dynamic Scheduling: 컴파일러가 명령어들의 dependency들을 판단하고 명령의 실행 순서를 바꿔주는 방식이다.
- CDC Scoreboarding
- Tomasulo algorithm & register renaming
Control Hazard
파이프라인이 branch에 대해 잘못된 결정을 내릴 때 발생하는 instruction 버림 현상이다. 분기에 의해 발생한다.
위에서 보여줬던 이 그림이 Control Hazard에 해당한다. Instruction 3의 branch로 인해 4~7에 해당하는 instruction들이 버려지는 모습을 볼 수 있다. 스테이지의 개수가 늘어남에 따라 버려지는 instruction의 수도 많아지므로 성능을 크게 하락시키는 원인이 될 수 있다.
Control Hazard 해결 방법
- multiple streams: 각 분기에 대한 스트림을 둬서 처리하는 방식(True / False 양쪽에 대해)
- Prefetch branch buffer: 분기가 인식되면 분기 대상을 미리 가져와서 분기 명령이 실행될 때까지 저장. 분기가 시작되는 시점에는 이미 fetch 된 정보를 사용.
- Loop buffer: 일종의 캐시 개념. 일련의 instruction들에 대한 정보 관리
- Branch prediction: 다음 실행할 브랜치를 예상하여 실행
- Delayed Branch
Branch Prediction
어떤 브랜치가 사용될지 예측하는 방법.
- 정적 예측 방법: 과거 실행 히스토리에 의존하지 않고 예측하는 방식
- Predict never taken: 브랜치가 안된다는 가정 하에 순서대로 명령을 실행하는 방식
- Predict always taken: 브랜치가 된다는 가정 하에 타겟 위치의 명령을 실행하는 방식
- Predict by opcode: instruction의 opcode에 기반해서 특정 opcode에 대해서는 branch, 아니면 순서대로
- 동적 예측 방법: 과거 실행 히스토리를 기반으로 전략을 수립하는 방식.
- Taken/not taken switch: 실행할 때 상태 기반으로 브랜치를 할지, 말지 결정하는 방식
- Branch history table: 히스토리 테이블을 두고 과거 값들을 이용하여 브랜치 여부를 결정


Taken & not Taken은 Taken으로 시작하여 연속으로 2번 반대 결과가 나오면 반대 상태로 간다. 예를 들어 Taken 상태에서 연속으로 2번 브랜치를 무시하는 결과가 발생하면 not Taken 상태가 되어 다음 브랜치는 건너 뛰는 상태가 된다.

Branch history table 전략은 내부적으로 과거 instruction들에 대한 상태 기록을 남긴다. 새로운 브랜치가 들어오면 과거 기록들을 뒤져서 일정한 로직에 따라 어떻게 대응할지 결정한다.
two-level adaptive predictor
if문이 3번 실행되면 3번째 실행되는 문장은 과거 2번의 기록을 기반으로 실행되는 방식.

- interrupt
- 하드웨어에서 발생하는 신호로, 프로그램 실행 중 아무때나 발생할 수 있음.
- maskable: CPU 명령으로 비활성화 또는 무시할 수 있는 타입
- nonmaskable: CPU 명령으로 비활성화할 수 없어 바로 실행되는 타입
- exception
- 소프트웨어에서 잘못된 명령을 실행할 때 발생.
- interrupt vectore table
- 모든 타입의 인터럽트에 대해 숫자가 할당된 타입.
- 숫자는 인터럽트 벡터 테이블 안에서 인덱스 값으로 사용됨.

ARM 프로세서
- 동일한 크기의 레지스터 여러개를 가짐.
- load/store 모델을 기반으로 하며, 모든 동작은 메모리에서 직접 수행되는 대신 레지스터에서 수행됨.
- 32비트의 표준 또는 16비트의 thumb instruction set
- ALU와 shift register unit이 구분되어 있어 동시에 수행 가능.
- addressing mode 개수가 적으며, 주소는 레지스터 및 instruction 필드에 의해 결정됨.
- loop 동작을 위한 auto increment / decrement addressing이 존재.
- instruction 자체가 조건부 실행이 가능하도록 설계되어 있어 파이프라인에 대한 효율이 좋음

ARM의 프로세서 모드
총 7개의 프로세서 모드가 있으며, 6개는 시스템을 위한 목적.
- 유저 모드: 대부분의 프로그램이 동작하는 모드. 이 모드에 있는 프로그램은 exception을 발생시키지 않는 한 모드를 변경하거나 보호되는 시스템 자원에 접근할 수 없음.
- 나머지 모드: privileged mode로 시스템 소프트웨어를 동작시키는데 사용됨.
다양한 privileged mode가 존재하여 os가 다양한 상황에서 대처하기 쉬우며, 특정 레지스터들은 privileged mode에서만 사용되어 컨텍스트 스위칭을 더 빠르게 수행할 수 있다고 한다.
'CS > 컴퓨터구조' 카테고리의 다른 글
| [컴퓨터구조] ILP & superscalar processor(1) (0) | 2022.11.23 |
|---|---|
| [컴퓨터구조] RISC (1) | 2022.11.22 |
| [컴퓨터구조] Instruction set(2) (0) | 2022.11.09 |
| [컴퓨터구조] Instruction set(1) (1) | 2022.11.07 |
| [컴퓨터구조] I/O (0) | 2022.11.03 |



