현재 글은 컴퓨터 구조와 아키텍처 서적 및 대학에서 들은 강의를 기반으로 한다.
Addressing Mode
컴퓨터 내에는 다양한 주소 지정 방식이 존재한다. 각각의 모드는 저마다 존재 이유가 있지만 모든 아키텍처가 반드시 제시되는 주소 모드를 구현할 필요는 없으며 최적화나 아키텍처의 설계 의도에 따라 많이 변형될 수 있다.
Basic Addressing Modes
컴퓨터에서 일반적으로 다음과 같은 주소 지정 방식을 고려할 수 있다. 이러한 주소 지정 방식들은 컴퓨터 내에서 상황에 따라 instruction 마다 각각 addressing mode이 설정된다.
- Immediate: Instruction 내에 데이터 포함
- Direct: Instruction 내에 주소 포함
- Indirect: Instruction이 가리키는 주소에 실제 주소가 저장되어 있음
- Register: 레지스터 주소 포함
- Register Indirect: Instruction이 가리키는 레지스터에 실제 주소가 저장되어 있음
- Displacement: 주소를 계산할 때 Instruction + Register
- Stack: 스택의 Top이 곧 주소

Immediate Addressing
Instruction 자체에 데이터가 들어 있는 경우를 의미한다. 따라서 메모리를 거치지 않고도 바로 데이터를 얻을 수 있다.
- 알고리즘: Operand = A
- 장점: Instruction만 가져오면 바로 데이터를 사용할 수 있기 때문에 메모리에 접근하지 않아도 된다.
- 단점: 저장할 수 있는 데이터의 크기가 instruction의 operand로 제한되므로 사용이 제한적일 수 있다.
- 사용 예시: 상수 값을 저장할 때 사용한다.
Direct Addressing
Instruction 내에 데이터의 주소가 들어 있다. 해당 메모리 주소에 접근하면 데이터를 얻을 수 있다.
- 알고리즘: EA = A
- 장점: 주소에 접근하면 바로 데이터를 가져올 수 있으므로 간단한 편이다.
- 단점: 주소가 Instruction 내에서 표현될 수 있어야 하므로 가리킬 수 있는 메모리 공간이 제한적이다.
- 사용 예시: 글로벌 변수를 저장할 때 사용한다.
Indirect Addressing
Instruction 내에 주소가 들어 있다. 해당 주소는 메모리 상의 또 다른 위치를 가리키며, 그 위치로 접근하면 데이터를 얻을 수 있다. 일종의 포인터처럼 동작한다고 보면 된다. instruction으로 메모리 접근 -> 주소로 데이터 접근
- 알고리즘: EA = (A)
- 장점: 메모리 한 워드의 크기를 전부 주소를 지정하는 데 사용할 수 있어 참조 가능한 메모리 공간의 크기가 커진다.
- 단점: 메모리에 2번 접근해야 하므로 속도를 느리게 만든다(메모리 접근 시간은 레지스터의 몇백 배에 해당한다).
- 사용 예시: 포인터 변수를 저장할 때 사용한다.
Register Addressing
Instruction 내에 주소가 저장되어 있는데, 이게 레지스터의 주소이다. 대부분의 시스템에서 레지스터의 개수는 몇백 개 정도로 메모리 공간에 비해 표현해야 하는 범위가 좁다는 특징이 있다.
- 알고리즘: EA = R
- 장점: 메모리에 접근하지 않으므로 속도가 빠르다. instruction 내에서 레지스터를 표현하기 위한 비트의 수가 적다.
- 단점: 컴퓨터 내에서 레지스터의 개수가 그리 많은 편이 아니라 제한된 크기를 가진다.
- 사용 예시: 임시 변수를 저장할 때 사용될 수 있다. 메모리 마냥 계속 점유하면서 사용하지는 않는다.
Register Indirect Addressing
Instruction 내에 레지스터의 주소가 저장되어 있으며, 해당 레지스터 내에는 데이터의 주소를 가리키므로 간접적으로 데이터를 얻을 수 있는 방식이다.
- 알고리즘: EA = (R)
- 장점: 메모리 한 워드를 주소 지정에 사용할 수 있어 표현 가능한 주소 공간이 넓어지며, 레지스터와 메모리를 각각 1번 접근하므로 Indirect Addressing 방식에 비해 속도가 빠르다.
- 단점: 레지스터의 개수 자체가 제한되어 있으며, 여전히 메모리에 한 번은 접근해야 한다.
- 사용 예시: 임시 포인터 변수에 사용된다.
Displacement
주소를 계산할 때 레지스터 주소와 메모리 주소를 결합하여 실제 주소를 얻는 방식이다.
- 알고리즘: EA = A + (R)
- 장점: 융통성이 높아 다양한 용도로 사용될 수 있다.
- 단점: 두가지 주소를 결합하여 연산하기 때문에 다른 주소에 비해서는 복잡한 편이다.
- 사용 예시: 스택 내의 로컬 변수를 표현하는 등...
Stack

스택의 Top을 현재 주소로 잡고 연산을 진행한다. 메모리를 스택 형식으로 사용하는 zero-address instuction에 적합하다. 예를 들어 두 변수를 더하고 싶은 경우 PUSH A -> PUSH B -> ADD -> POP을 통해 결과를 얻을 수 있다.
- 알고리즘: EA = TOP
- 장점: 메모리 접근이 전혀 필요하지 않다.
- 단점: 사용 가능한 경우가 문제를 스택 형식으로 처리할 수 있는 상황으로 제한된다.
x86 주소 지정

인텔의 x86 아키텍처는 Displacement + 세그멘테이션을 통해 실제 주소를 연산한다.
- Base Register: 기본 주소
- Index Register: 인덱스 주소. Scale factor을 곱함으로써 byte, word, dword 등의 자료형을 표현할 수 있다.
- Segment Register: 세그먼트의 주소를 저장하는 레지스터. CS(code), DS(data), ES(extra), SS(stack)처럼 프로그램 내의 특정 구성요소를 가리키는 레지스터와 주소 공간을 늘리기 위해 추가된 FS, GS가 있다.
- Descriptor Register: 세그먼트의 메모리 상 주소, 크기 및 접근 권한 등을 담고 있는 레지스터로, Segment Register의 값을 기반으로 특정 세그먼트의 정보를 얻는다.
- Base: 메모리 상 세그먼트의 시작 주소
- Limit: 세그먼트의 길이
- Access Rights: 접근 권한. 각 세그먼트의 속성에 따라 허용될 수 있는 접근 권한이 다른데, 이를 표현한다.
- system segment의 경우 일반 유저의 접근을 완전히 막아야 한다.
- code segment에는 프로그램의 코드(instruction)가 저장된다. 이때 해당 정보는 일반 유저가 마음대로 읽거나 쓸 수 있어서는 안 된다. 예를 들어 스택 오버플로우를 이용하여 코드를 수정하는 등의 동작을 하면 프로그램이 망가지게 될 것이다. 따라서 해당 영역의 값을 읽거나 쓸 수 없도록 접근 권한을 설정해야 한다.
- Linear Address: 세그먼트 정보 및 deplacement을 통해 얻은 주소

ARM 주소 지정
ARM은 Load/Store Addressing을 이용하여 주소를 지정한다고 한다. displacement와 유사해 보인다.

예를 들어 STRB r0, [r1, #12] 라는 코드를 실행하면 r1은 기반 주소, r2는 오프셋(register 주소 또는 immediate value)으로 간주하여 두 값을 더해 실제 주소를 연산한다. 위 예시에서는 r1 + #12 = 0xC = 0x20 C 주소를 얻었고, 해당 위치에 r0의 값을 저장했다. 이 방법은 두 레지스터의 주소 값을 더하지만, base register의 주소가 변경되지는 않는다.
이러한 방식에서 파생되는 것으로 주소 연산과 base register 업데이트를 동시에 하는 방식들도 존재한다. 각각 preindex, postindex라고 하며 C 언어에 있는 ++A, A++ 연산자와 유사하게 동작한다.
- preindex: 주소 관련 레지스터를 연산하여 base register을 업데이트 한 후, 이 주소에 대해 연산을 수행한다.
- C언어로 치면 (++(*ptr)) 같은 느낌 (주소 연산 후 명령 처리)
- postindex: 현재 base register 주소에 대해 연산을 진행한 후 주소를 업데이트한다.
- C언어로 치면 ((*ptr)++) 같은 느낌 (명령 처리 후 주소 연산)


언급된 두 방식은 주소 연산과 명령을 동시에 수행하는데, 이런 것들이 addressing mode에 왜 필요할까?
프로그램 최적화 과정에서 큰 비중을 차지하는 것 중 하나는 loop optimization이다. 이때 한 루프 내에서 1 연산 1 주소 값 증가 연산을 수행한다고 가정해보자. 이 경우 루프를 한번 돌 때 2개의 instruction이 소요될 것이다. 이때 연산 및 주소값 증가가 한 번의 연산으로 수행될 수 있다면 루프 한 번에 1개의 instruction이 소요된다. 루프를 10000번 돈다고 치면 확정적으로 10000번의 연산을 줄일 수 있는 셈이 되는 것이다.
즉, 두 방식은 loop optimization 과정에 필요하다. 배열처럼 연속적인 데이터에 반복하여 접근하는 경우 연산 및 주소 증가를 동시에 수행하여 최적화를 진행하는 것이 목적이라고 볼 수 있다.
instructions
- Data Processing Instruction
- register addressing 또는 register + immediate addressing 방식만 사용(데이터 쓰면서 읽기 이런 거 안됨)
- 레지스터의 값은 5가지의 shift operator을 통해 값이 변경될 수 있다. 자유로운 shift가 ARM의 특징 중 하나라고...
- Branch Instruction
- immediate만 허가
- instruction은 24 비트로 구성
- Load Store Multiple Accessing : 프로시저를 콜 할 때 파라미터 전달에 대한 오버헤드를 줄이는 목적
- 여러 개의 데이터를 동시에 접근하여 읽거나 쓰는 방식을 의미한다. 프로시저를 콜 할 때 파라미터의 정보를 스택을 통해 주고받게 되는데, 이 과정은 상당히 오버헤드가 큰 작업이다. 이때 한 번에 여러 데이터를 동시에 load 또는 store 할 수 있다면 오버헤드가 줄어들 수 있다. 아래 그림 기준으로 load & store에 대해 나타나는 오버헤드가 1/3 줄어드는 효과를 기대할 수 있다고 한다.

Instruction Format
- 필드의 일관성 측면에서 instruction의 비트를 정의
- opcode, addressing mode, operand을 명시 또는 암시적으로 instruction에 반영해야 한다.
- 대부분의 instruction은 하나 이상의 포맷으로 사용된다.
Instruction Length
instruction의 길이는 다음 요소들에 영향을 주거나 받을 수 있다.
- Memory Size
- Memory Organization
- Bus Structure
- Processor Complicity
- Processor Speed
일반적으로 Instruction의 길이는 시스템이 버스를 통해 한번에 전송할 수 있는 최대 길이(memory-transfer length)를 가진다. 예를 들어 32비트 컴퓨터는 한번에 32비트를 전송할 수 있으므로, instruction의 길이도 자연스럽게 최대치인 32비트로 설정된다. 그 이상의 길이라면 하나의 instruction 전송에 2사이클 이상이 필요하기 때문에 효율적이지 못하고, 그보다 짧다면 남은 비트가 낭비되기 때문이다.
Allocation bits
instruction 내에서 어떤 정보를 얼마나 할당할지도 중요한 요소 중 하나다. 다음과 같은 것들을 고려할 수 있다.
- Number of Addressing modes
- Number of Operands
- Register vs Memory
- Number of Register sets
- Address Range
- Address Granularity: 주소 지정을 어떻게 할지. byte냐 word냐 ...

Variable Length Instruction
instruction의 길이가 가변적인 방식.
- 고정된 길이가 아니라고 해도 간단하고 효과적으로 처리되어야 한다.
- 가변 길이의 instruction을 해석하기 위해서 프로세서가 더 복잡해진다.
- 가변 길이라고 해도 word의 배수 형태를 띄어야 한다. 예를 들어 1 word가 16비트인 시스템이라면 주소 체계는 16의 배수 꼴로 나타나야 한다. 만약 21비트 길이의 instruction을 사용한다면 프로세서는 16비트를 해독한 후 다음에 오는 instruction이 5비트인 경우를 판단하게 만들어야 하므로 안그래도 복잡한 프로세서가 더 복잡해진다. 어차피 전송되는 단위가 1 word라면 word의 배수로 만드는 것이 프로세서가 이해하기 좋다.
- 잘 사용되는 instruction의 길이는 짧게, 거의 사용되지 않는 instruction의 길이는 길게 구성하여 최대한 긴 instruction을 사용하지 않도록 구성한다.

x86의 instruction format

x86 아키텍처는 복잡한 주소 지정 체계에 맞게 instruction format도 참 복잡하다.
- Instruction prefix: 동기화 목적으로 존재하는 데이터로, 현재 진행중인 작업이 끝날 때까지 아무도 메모리 버스를 사용하지 못하도록 lock을 걸 때 사용한다고 한다.
- Segment override: x86는 주소를 지정하는 과정에서 세그먼트 정보를 사용한다. 세그멘테이션 과정에서 데이터들은 자신에게 맞는 세그먼트 위치를 가지는데, 이 위치를 변경하고 싶은 경우(Stack 말고 Data에서 처리하고 싶다든지) 이 값을 수정하여 저장되는 세그먼트 위치를 바꿀 수 있다고 한다.
- Operand size override / Address size override: operand 나 address 길이가 기본 값으로 부족한 경우 이를 변경하고 싶을 때 사용한다고 한다.
ARM의 instruction format

ARM의 모든 instruction에는 Condition Code가 존재한다. Condition Code에 나타나는 비트의 조합을 기반으로 상태를 얻어 conditional branch와 동작 수행이 하나의 instruction으로 구성되기 때문에 조건부로 실행되는 명령을 실행할 때 명시적인 branch 작업이 필요하지 않다.
예를 들어 다음과 같은 코드를 고려하자.
while (i != j)
{
if(i > j)
i -= j;
else
j -= i;
}i != j 조건에 따라 while 문 내에서 두 값은 명백히 다르다. i > j 인 경우 i -= j 연산을 진행하고, i < j인 경우 j -= i 연산을 진행한다. 이때 if문 조건을 branch 명령이 존재하는 경우와 존재하지 않는 경우에 대한 어셈블리 코드를 고려하자.
#1. branch와 execution이 구분되는 경우
Loop: CMP Ri, Rj // Ri, Rj의 값을 비교한다
BL A // Ri < Rj인 경우 점프
SUB Ri, Ri, Rj // Ri > Rj인 경우 i -= j
B B // B로 점프
A: SUB Rj, Rj, Ri // Ri < Rj인 경우 j -= i
B: BNE loop // Ri != Rj인 경우 루프
#2. branch와 execution이 동시에 수행되는 경우
Loop: CMP Ri, Rj
SUBGT Ri, Ri, Rj
SUBLT Rj, Rj, Ri
BNE Loop전자는 branch와 instruction execution이 구분되는 경우고, 후자는 branch와 instruction execution을 동시에 수행하는 경우이다. 딱 봐도 후자의 instruction 실행이 훨씬 적기 때문에 대략 효율적이라는 것은 짐작이 된다.
이러한 구조는 특히 파이프라인을 구성할 때 큰 도움이 된다. 우리가 작성한 코드는 컴파일러의 최적화 과정에서 실행 순서가 변경될 수 있다. 이때 branch와 실제 동작이 구분되어 있는 경우 이 둘 사이에는 의존 관계가 존재하기 때문에 컴파일러 마음대로 실행 순서를 변경할 수 없어 최적화 과정을 방해한다. 반면 branch 및 동작이 하나의 instruction으로 묶이는 ARM의 경우 각 instruction 사이의 branch에 의한 의존 관계가 없어지므로 순서를 바꾸더라도 크게 문제되지 않는다.
위 코드에서, 전자의 경우 두 SUB 연산의 자리를 바꾸면 Ri > Rj 일 때 j -= i 명령을 실행하게 된다. 이는 branch와 SUB 연산 사이에 의존 관계가 존재하여 연산의 순서를 쉽게 바꿀 수 없기 때문이다. 반면 후자의 경우 두 SUB 연산의 위치를 바꾸더라도 어떤 문제도 없다. 전자에서 의존 관계를 만든 두 명령이 하나로 통합되어 의존 관계가 사라지기 때문이다.
이러한 예시에서 볼 수 있듯이 ARM의 instruction은 파이프라인을 적용하기 좋게 설계되어 있다.
Immediate Constants

ARM instruction의 특징 중 하나가 다른 명령과 shift 명령을 동시에 수행할 수 있는 것이라고 하는데, immediate 상수에 shift 연산을 수행하여 더 넓은 값을 표현하는 것도 가능하다고 한다.
Thumb Instruction Set
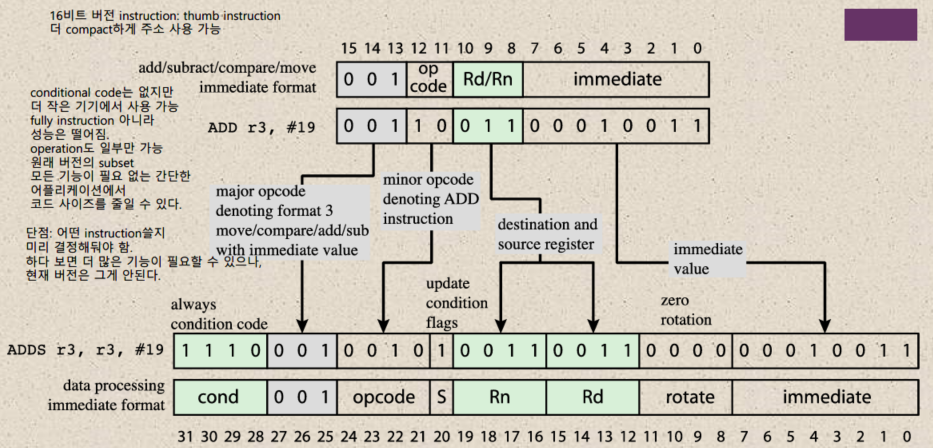
ARM의 Instruction은 32비트 길이를 가진다. 그러나 임베디드 환경처럼 성능이 제한되거나 필요한 기능이 일부로 한정되는 경우 주소 길이를 줄여 더 컴팩트한 형태로 주소를 사용할 수도 있다. Thumb instruction set은 ARM instuction의 기능 및 성능을 한정하여 주소 길이를 16비트로 줄여 사용하는 방식을 의미한다.
Thumb instruction set에는 conditional code가 없으며, op code의 길이도 2로 제한되어 ARM에서 제공하는 명령 중 4개만 선택할 수 있다. ARM에서 제공하는 전체 기능이 필요하지 않은 간단한 어플리케이션에서 코드 사이즈를 줄일 수 있다는 장점이 있지만, 프로그램 개발 과정에서 4개 instruction에 포함되지 않는 명령이 필요하더라도 이를 확장하여 사용할 수 없다는 단점이 존재한다.
Thumb-2 Instruction Set
기존 버전에서 instuction을 확장할 수 없는 문제점을 보완한 방식. Cortex-M 마이크로 컨트롤러에서 지원한다.
- 16비트 thumb instruction과 32bit instruction을 혼합하여 사용할 수 있다. 단, 여전히 condition은 없다.
- If - Then instruction을 도입하여 condition field 기능 대부분을 처리할 수 있다고 한다.
- ARM ISA 수준의 퍼포먼스 레벨을 도입하면서 thumb 수준의 code dencity을 구현할 수 있다.
'CS > 컴퓨터구조' 카테고리의 다른 글
| [컴퓨터구조] RISC (1) | 2022.11.22 |
|---|---|
| [컴퓨터구조] 프로세서 구조 및 기능(1) (0) | 2022.11.17 |
| [컴퓨터구조] Instruction set(1) (1) | 2022.11.07 |
| [컴퓨터구조] I/O (0) | 2022.11.03 |
| [컴퓨터구조] External Memory(2) (0) | 2022.10.31 |



