현재 글은 컴퓨터 구조와 아키텍처 서적 및 대학에서 들은 강의를 기반으로 한다.
Flynn's taxonomy
flynn이라는 사람이 병렬 동작을 염두에 두고 제시한 컴퓨터 아키텍처의 분류 방식으로, instruction stream 및 data stream의 구성에 따라 크게 4개로 분류된다.
- SISD: Single Instruction Single Data
- SIMD: Single Instruction Multiple Data
- MISD: Multiple Instruction Single Data
- MIMD: Multiple Instruction Multiple Data

SISD

단일 프로세서가 하나의 메모리 데이터에 대해 단일 연산을 수행하는 방식. 가장 간단한 구조로, 현재는 기본이 멀티 코어 시스템이기 때문에 이러한 시스템을 볼 일이 많지는 않다. Uniprocessor으로 분류된다.
SIMD

하나의 Control unit에서 특정 연산을 수행하라고 전파하면 서로 다른 processing unit들이 자신들이 가진 고유의 local memory에서 데이터를 가져와서 동일한 연산을 처리하는 방식이다. SIMD instruction의 경우 길이가 긴 자료형을 이용하여 "하나의" 메모리에서 여러 데이터를 가져와 연산을 진행하지만, SIMD 구조는 메모리 자체가 여러 개로 구성되며 동일 연산을 수행한다.

SIMD는 vector 데이터를 처리하기에 적합한 구조를 가지고 있어 vector processor이라고 부른다(연산 방식 측면). 한편으로 Processing Unit들이 배열처럼 나열되어 있어 Array Processor이라고 부르기도 한다(하드웨어적 측면).
그러나 SIMD 구조는 현실에서 거의 사용되지 않으며, 일부 실험적 머신으로만 제작되었다. 그 이유는 SIMD 구조가 너무 많은 하드웨어를 요구하기 때문이다. SIMD는 각 라인에 대해 개별적인 Processing Unit 및 메모리가 별도로 존재해야 하기 때문에 비용이 비싸다. 보통 SIMD의 경우 vector 데이터 처리 목적으로 사용되는데, 해당 데이터를 처리할 때 파이프라인 기법을 이용하면 단일 머신으로 충분하기 때문에 비용이 감소하면서 어느 정도 성능도 보장된다는 장점이 있다. 즉, 파이프라인 기법이라는 대체제가 존재하므로 굳이 큰 비용을 들여가면서 SIMD 구조를 구현할 이유가 없다.
MISD
하나의 데이터에 대해 여러가지 연산을 수행하는 구조다. 사실 이런 연산 자체가 범용적 측면에서 크게 의미가 없기 때문에 단 한 번도 상업적 측면에서 구현된 적이 없다. 위키피디아에 따르면 우주비행선에서 제한적으로 사용된다고 한다.
MIMD
여러개의 프로세서가 서로 다른 데이터에 대해 서로 다른 연산을 수행하는 구조로, 현대 프로세서가 가지는 전형적인 구조라고 할 수 있다. MIMD는 세부적으로 3개 분류로 나뉠 수 있다.
- Shared Memory
- SMP(Symmetric Multiprocessor)
- NUMA
- Distributed Memory
- Cluster
Shared Memory

shared memory 방식은 코딩을 통한 병렬성 구현이 간단하다는 장점이 존재한다. 반면 메모리를 공유하는 특징 때문에 참여하는 프로세서의 수가 많아짐에 따라 resource, data 등 여러 가지 경쟁으로 인한 충돌이 발생하여 성능 향상이 점점 줄어들기 때문에 대규모 시스템을 구현하는 데는 무리가 있다.
메모리 공유 환경에서는 0.8 rule 이라는 것이 있다고 한다. 0.8 rule은 공유 메모리 환경에서 프로세서를 하나 추가하는 경우 속도 향상이 0.8n으로 나타난다는 경험에 근거한 규칙으로, 프로세서가 10개만 되더라도 속도 향상이 0에 가까워지는 것을 고려하면 메모리 공유 방식이 대규모 시스템에 부적합함을 알 수 있다.
그러나 슈퍼컴퓨터와 같은 대규모 시스템이 아닌 경우 - 예를 들어 범용 컴퓨터를 사용하는데 성능을 조금 더 높이고 싶은 상황에서는 구조가 간단한 shared memory 방식도 충분히 의미가 있다. 또한 shared memory 방식의 경우 기존 코드를 간단하게 병렬로 처리할 수 있게 도와주는 다양한 방법이 존재하기 때문에 (ex openMP), 나쁜 방법은 절대 아니다.

SMP
https://en.wikipedia.org/wiki/Symmetric_multiprocessing
2개 이상의 유사한 프로세서가 하나의 공유 메모리와 I/O 모듈에 연결되는 방식. 현대 프로세서의 각 코어들은 대체적으로 동일한 성능을 가지며, 하나의 메모리 및 I/O 모듈을 이용한다. 즉, SMP는 현대 프로세서의 대중적인 구조라고 할 수 있다. 메모리에 대한 접근 속도는 어떤 프로세서든 동일한 것이 특징이다.
시스템은 각 프로세서가 수행하는 작업(task, job, data 등 포함) 사이의 동기화를 위해 하나의 OS에 의해 관리된다.
SMP의 연결 구조(network)
SMP가 사용하는 연결구조는 크게 3 종류로 나눌 수 있다.
- bus
- crossbar switch / multiport memory
- Multistage Interconnection Network
Bus
컴퓨터 내에서 데이터 전송 용도로 자주 사용하는 버스는 broadcasting 방식으로 데이터를 전달할 수 있다. 일반적으로 위 제시된 3가지 방법 중 가장 구조가 간단하고 저렴한 편이라 많이 사용된다. 하지만 하나의 버스에 여러 개의 프로세서 및 장치가 연결되는 경우 버스 사용권을 두고 경쟁하는 문제가 발생하여 성능이 크게 떨어진다는 단점이 있다.
이러한 버스의 단점을 방지하기 위해 multi bus / heirarchical bus의 형태를 띄거나 ring 구조를 가지기도 한다.
Ring
https://blaxsior-repository.tistory.com/156
위 글의 DCA 파트에서 설명한 구조이다. 버스 방식보다 성능이 좋으며, 특히 네트워크 로드가 큰 경우 효율적이다. 연결성을 관리하기 위한 노드를 두는 대신 책임을 분산하여 가질 수 있다. 다만 중간에 고장이 발생하면 ring 내에서 데이터가 돌지 못하므로 전체 네트워크에 영향을 줄 수 있으며, 이를 방지하기 위해 ring의 개수 자체를 늘리거나 고장 구역을 차단하기 위한 스위치를 가진다고 한다.
Crossbar

다수의 프로세서 및 메모리가 존재하는 환경에서 이들 사이를 연결하는 접점에 스위칭 소자를 두고 해당 스위칭 소자들을 조절하며 프로세서와 메모리를 연결하는 방식이다. 경로를 연결할 때 스위치에 모순이 발생하지 않는다면 한 번에 최대 N개의 프로세서를 메모리와 연결할 수 있으므로 성능이 매우 좋다. 이때 스위칭 소자의 개수에 따라 성능이 결정되기 때문에 성능을 높이기 위해서는 큰돈이 필요하며, N개의 프로세서를 M개의 메모리와 연결하기 위해서는 M*N개의 스위칭 소자가 필요하므로, 비용은 O(N2)을 따른다.
Multistage Interconnection Network
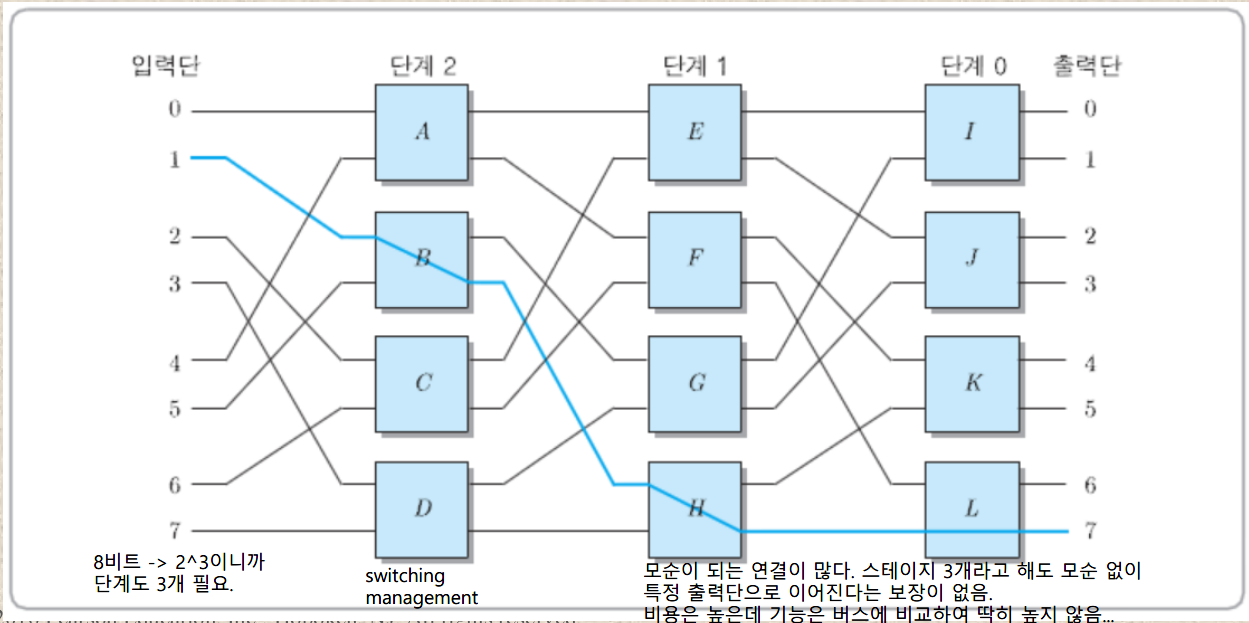
bus와 crossbar을 절충한 형태로, 여러개의 스테이지를 기반으로 입출력의 매핑이 가능한 구조이다. 각 스테이지마다 입력단이 섞이며(shuffle connection) 데이터를 교환할 수 있다(shuffle exchange)는 특징이 있다. 단 crossbar과는 달리 모든 스위치가 연결되어 있는 것이 아니라 모순이 자주 발생하며, 특정 연결 조합의 경우 동시에 사용할 수 없다. 예를 들어 위 그림의 경우 1-7 연결을 이용하고 있다면 5-4 연결은 B-H 연결이 불가능하여 동시에 수행될 수 없다.
연결의 개수가 N개라고 할 때 총 log 2 N 개의 스테이지가 필요하며, 2개 입력 단위로 교환을 진행하므로 각 스테이지마다 1/2N개의 스위치 박스가 필요하다. 따라서 필요한 전체 스위치 박스의 개수 및 가격은 O(N*logN)을 따른다.
crossbar에 비해 가격이 낮고 bus 방식보다 성능이 좋은 것은 맞지만 전체적으로 crossbar의 가격 및 bus의 성능에 가까운 퍼포먼스를 보이는 문제점이 있어 상용화된 적은 거의 없으며, 실험적인 용도로 일리노이 대학, 뉴욕 대학 등에서 구현한 적이 있다고 한다.
shuffle 방식, 알고리즘, 스위치 박스의 구조 등의 측면에서 매우 많은 연구가 진행되었다고 한다.
NUMA(Nonuniform Memory Access)
각 프로세서마다 구분된 물리적 메모리를 가지되, 논리적으로는 하나의 메모리로 취급되는 구조. 한 프로세서 입장에서 다른 프로세서의 메모리를 마치 자신의 로컬 메모리인 것 "처럼" 접근할 수 있게 된다.
이때 프로세서 외부의 메모리의 경우 접근하기 위해 외부 연결이 필요하기 때문에, 접근하는 위치에 따라 메모리 접근 속도가 달라진다는 특징이 있다. 가령 특정 프로세서가 자신과 직접 연결된 메모리를 접근하는 경우 빠르게 읽을 수 있겠지만, 그게 아니라면 타 프로세서를 거쳐야 하므로 속도가 느릴 것이다.
물리적 수준에서는 메모리 접근이 단순 load & store 방식이 아니라 message passing 등을 통해 수행될 수 있지만, 논리적 수준에서는 load & store을 통해 접근할 수 있다는 것이 특징이다.
Distributed Memory
Cluster / MPP(Massively Parallel Processing)
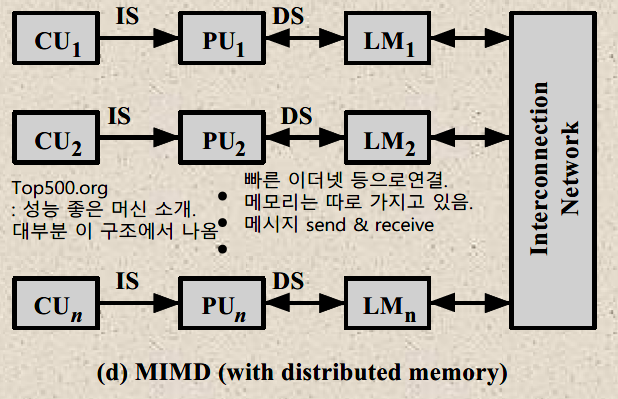
클러스터 방식은 다수의 컴퓨터(각각 구분된 메모리/프로세서)들을 통해 연산하되 충분히 빠른 네트워크를 통해 메시지를 교환함으로써 각 노드의 데이터를 교환하는 방식이다. 구현하기 어렵지만, shared memory 방식에서 발생하는 메모리에 대한 충돌로 인한 문제가 발생하지 않아 성능이 좋으므로, 대규모 병렬 시스템이 필요한 경우 대안이 없다.
Massively Parallel Processing은 프로그램을 여러 부분으로 나누어 여러 개의 프로세서에게 각 부분을 동시에 실행하도록 시키는 방식이다. 클러스터와 거의 동일하지만, 각 노드가 개별적인 PC의 역할은 수행할 수 없는 경우라고 한다.

Bus

위 SMP의 연결 구조를 설명할 때 언급했듯이 버스는 구조가 간단하고 가격이 저렴하다는 점에 있어서 컴퓨터 내에서 자주 사용된다. 구체적으로 장단점을 열거하면 다음과 같다.
- 장점
- Simplicity: 구조가 간단하여 프로세서 구조 설계가 쉬워진다.
- Scalability: 프로세서를 버스에 연결함으로써 시스템을 쉽게 확장할 수 있다. 반면 crossbar이나 MIN의 경우 처음부터 입력 및 출력 개수가 정해져 있으므로, 프로세서 및 메모리 확장을 위해서는 설계 구조 자체를 바꿔야 한다.
- Reliablity: 버스는 본질적으로 수동적 매체로, 연결된 장치 중 하나가 망가진다고 전체 시스템이 고장 나지는 않는다. 반면 ring 구조의 경우 연결된 장치 중 한 부분만 망가지더라도 데이터가 원활하게 순환되지 않을 수 있다.
- 단점
- Performance: 버스에 연결된 여러 장치들은 데이터 전송을 위해 버스 이용권을 두고 경쟁하는 관계에 있으므로 연결되는 장치의 개수가 많아질수록 충돌이 많이 발생하여 성능이 감소한다.
버스에 대한 경쟁이 심화될 수록 전체 시스템의 성능이 낮아지므로 각 프로세서는 내부적으로 캐시를 운용하여 버스를 통한 메모리 접근 횟수를 최소화해야 한다.
Cache Coherence
다수의 프로세서가 각자 캐시를 도입하는 경우 프로세서의 연산에 따라 데이터의 일관성이 깨질 수 있다. 따라서 캐시 및 메모리 내 데이터의 일관성을 유지하기 위한 방법이 요구될 수 있으며, 이 과정에서 데이터 전송을 위해 버스를 사용하여 버스 사용량이 증가하는 오버헤드가 존재한다. 소프트웨어 및 하드웨어적 접근 방법이 존재하나, 일반적으로는 하드웨어를 통해 캐시의 일관성을 관리한다.
Cache Coherence - Software Solution
운영체제나 컴파일러 수준에서 캐시 일관성을 처리하는 방식. RISC처럼 컴파일 타임에 프로그램에 발생할 오버헤드를 예상하여 미리 처리해둠으로써 런타임에 수행해야 할 오버헤드가 줄어들 수 있다. 이로 인해 문제 해결에 필요한 복잡성이 하드웨어 수준에서 소프트웨어 수준으로 이동할 수 있게 되는 장점도 있다.
그러나 실제로는 거의 사용하지 않는데, 기본적으로 소프트웨어를 이용하는 방식은 코드 분석처럼 정적 수준에서 이루어지므로 실제 환경에서 어떻게 동작하는지에 대한 정보를 얻을 수 없기 때문이다. 예를 들어 특정 데이터가 여러 위치에서 사용된다는 사실을 정적 분석을 통해 알아냈다고 가정해보자. 캐시에 데이터가 들어가기 위해서는 locality가 존재해야 하는데, 단순히 다양한 위치에서 사용되었다는 것은 이에 해당하지 않는다. 컴파일러는 실제 환경이 어떻게 동작할지에 대해 알 수 없으므로 해당 변수가 많은 위치에서 사용되더라도 자주 사용된다는 보장이 없어 최대한 보수적으로 해당 문제를 다루게 된다(conservative decision). 이 경우 변수는 캐시에 올라가지 않도록 설정될 것이다. 문제는 해당 데이터가 실제로는 자주 사용될 때 발생한다. 해당 데이터를 많이 접근함에도 불구하고 컴파일러에 의해 캐시에 적재되지 않도록 설정되어 miss가 반복되기 때문이다. 이처럼 실제 동작에 대한 보장이 없는 환경에서 예측을 하는 것은 캐시를 비효율적으로 사용하게 만들 수 있다. 따라서 현실에서는 소프트웨어 대신 하드웨어 측면에서 캐시 일관성에 접근한다.
Cache Coherence - Hardware Solution
런타임에 데이터의 상태 변화 또는 비일관성을 관측하여 이를 전파 또는 수정하는 방식이다. 일반적으로 캐시 일관성 프로토콜이라는 이름으로 불리며, 하드웨어 수준에서 처리되므로 운영체제 또는 사용자와 같은 상위 레벨에서는 캐시의 일관성이 어떻게 유지되는지 관측할 수 없으며, 이를 알 필요도 없게 된다. 사용자는 캐시 일관성 문제를 고민하지 않아도 되기 때문에 소프트웨어 개발에 집중할 수 있게 된다.
캐시 일관성 프로토콜에는 2종류가 존재한다.
- Directory Protocol: 각 프로세서 캐시 내의 정보를 디렉토리에 저장. 값 바뀌면 디렉토리 참조.
- Snoopy Protocol: 시스템이 버스를 계속 관찰하여 업데이트가 발생했을 때 이를 전파.
Directory Protocol
각 프로세서에 대해 캐시 데이터와 관련된 정보를 저장하고 있는 디렉토리라는 구조가 존재하는 방식이다. 특정 데이터가 업데이트 되면 디렉토리를 순회하여 동일 데이터를 가진 다른 프로세서들을 식별하고, 해당 프로세서들에게 수정 내역 또는 메시지를 보내 수정을 유도한다. 디렉토리는 보통 메모리 상에 보관된다.
일반적으로 복잡한 연결 방식을 많이 사용하는 고성능 시스템에 적합하다. 저렴한 매체인 버스를 Directory Protocol과 사용하는 경우를 생각해보자. 특정 프로세서의 캐시 값을 WRITE 명령을 통해 수정하면 시스템은 해당 변수의 변동을 감지한 후 메모리로부터 디렉토리 데이터를 읽어온다. 버스를 사용하는 경우 한번에 하나의 데이터만 버스 상에 존재할 수 있으므로 모두의 디렉토리 정보를 메모리로부터 읽어오기 위해서는 큰 시간이 요구되며, 이로 인해 심각한 오버헤드가 발생한다. 따라서 버스 구조는 Directory protocol과 사용하지 않거나, 사용하더라도 디렉토리를 메모리가 아니라 캐시처럼 충분히 빠른 매체에 보관할 필요가 있다.
Snoopy Protocol
각 프로세서 내에 있는 캐시 컨트롤러에게 책임을 분산시키는 방식으로, 캐시 컨트롤러는 다른 캐시들과 공유하고 있는 라인을 통해 전파되는 변동 사항을 감지하고 이에 대응하는 역할을 수행한다. 해당 라인 상에서 업데이트가 수행되면 다른 캐시들에게 브로드캐스트 방식으로 해당 사실을 알리는 것이 주된 동작이므로 버스 구조가 아니면 비효율적이다.
버스가 아닌 경우 네트워크에 연결된 모든 프로세서들에게 해당 사실을 알리기 위해 각각 전송할 필요가 있다. 예를 들어 한 네트워크에 10개의 프로세서가 연결되어 있다면 버스 구조에서는 한 사이클에 보낸 데이터를 모든 프로세서가 읽을 수 있으므로 1번의 브로드캐스트로 처리할 수 있지만, 크로스바나 MIN은 해당 데이터를 각각 보내야 하므로 더 긴 시간이 필요하게 된다.
타 캐시 업데이트 전략
멀티 프로세서 구조에서는 모든 프로세서 내의 캐시 일관성을 유지할 필요가 있는데, 크게 2가지 방식을 이용하여 이러한 문제를 다룰 수 있다.
- write update: 특정 캐시의 데이터가 변동될 때마다 변동 사항을 전파하여 일관성을 유지한다.
- write invalidate: 특정 캐시의 데이터가 변동되면 다른 캐시에게는 해당 데이터가 변동되었다는 사실만 알린다.
Write Update
캐시의 내용이 변동될 때마다 변동 사항을 전파하여 일관성을 유지하는 방식이다. 변동될 때마다 수정할 데이터를 전송해줘야 하기 때문에 네트워크 트래픽이 많이 발생하여 병목 현상이 나타나기 쉽다는 문제점이 존재하지만, 캐시 내의 데이터는 항상 최신 상태를 유지하므로 invalid로 인한 캐시 미스는 나타나지 않으므로 READ, WRITE가 비슷하게 자주 발생하는 상황에서는 Write Invalidate 방식에 비해 더 효과적이다.
Write Invalidate
캐시의 내용이 변동되면 수정되었다는 사실만 전파하고, 다른 캐시에게 해당 데이터가 필요한 시점에 전달하는 방식이다. 특정 데이터가 변동되었다는 사실을 알게 된 다른 캐시들은 해당 데이터를 invalid 상태로 전환하고, 나중에 해당 데이터가 필요한 시점에 최신 데이터를 가진 캐시에게 데이터를 요청하게 된다.
캐시를 읽는 경우가 쓰는 경우에 비해 매우 많은 상황에서 효율적이다. 쓰기 횟수가 매우 많은 경우 프로세서 캐시 내의 데이터 중 다수가 무효화되어 캐싱 효과를 잃고 다른 캐시에서 수정된 값을 읽어와야 하므로 차라리 캐시를 사용하지 않는 것이 나은 수준이 될 수도 있다.
각 캐시의 상태를 수정됨(Modified), 독점(Exclusive), 공유(Shared), 유효하지 않음(Invalid) 상태로 나타내어 데이터 전송을 관리하는 MESI 프로토콜을 이용한다.
MESI 프로토콜
https://blaxsior-repository.tistory.com/148
MESI 프로토콜은 SMP 구조에서 캐시 사이의 일관성을 유지하는데 사용되는 프로토콜로, 각 캐시 라인의 상태를 Modified, Exclusive, Shared, Invalid 4가지로 나누어 관리한다.
- Modified: 현재 캐시 라인이 수정되었으며, 다른 캐시에는 해당 데이터가 없다.
- Exclusive: 현재 캐시 라인은 원본(메인 메모리와 동일)이며, 다른 캐시에 존재하지 않는다.
- Shared: 현재 캐시 라인은 원본(메인 메모리와 동일)이며, 다른 캐시에 존재할 수 있다.
- Invalid: 현재 캐시 라인은 유효하지 않다.
현재 프로토콜의 장점은 캐시가 Modified 및 Exclusive 상태에 있는 경우 데이터를 독점적으로 가지고 있으므로 값을 변경하더라도 다른 캐시에 영향을 주지 않는다는 점이다. 이에 따라 두 상태에 있는 캐시의 update 사항은 다른 캐시에 알리지 않아 의미 없는 트래픽 소모를 줄일 수 있다.



다만, MESI 프로토콜에는 Shared 상태와 관련된 단점이 존재한다. Modified 상태에서 다른 캐시가 Shared Read을 요청하는 경우 데이터를 제공하고 Shared 상태로 전이하게 된다. 이때 Shared는 캐시 및 메인 메모리 상의 데이터 일관성을 보장해야 하므로 변동된 사항을 메모리 상에 반영할 필요가 있다(dirty line copyback).
문제는 메인 메모리의 속도가 캐시에 비해 매우 느리다는 사실이다. 변동이 발생하고, 해당 값을 다른 캐시에서 요청할 때마다 메모리에 쓰는 행위는 전체 명령 중 쓰기 비중이 높아짐에 따라 메모리 접근 횟수를 증가시키기 때문에 성능을 크게 낮출 수 있다. 특히 멀티코어 환경의 경우 코어 사이에서 R2 캐시 등을 통해 데이터를 직접 제공할 수 있으므로 반드시 메모리를 거칠 필요가 없다. 따라서 메인 메모리 상의 데이터는 쓰기 동작 이전까지 dirty 상태로 유지하고, 읽기 동작은 캐시 수준에서 처리하는 상황을 나타내기 위해 Shared가 아닌 다른 상태가 요구된다.
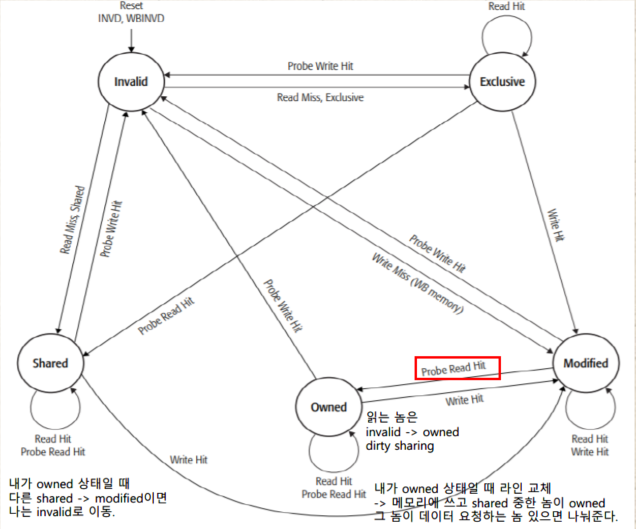
MOESI
MOESI 프로토콜은 기존 MESI 프로토콜에 새로운 상태 Owned을 추가하여 메모리에 데이터 변동을 반영하지 않고 캐시 간 Shared Read을 가능하게 하여 메모리 접근 횟수를 낮춘다.
MOESI 프로토콜이 성립하기 위해서는 메인 메모리의 개입 없이 캐시와 캐시 사이 데이터 전송이 가능해야 한다. 앞서 언급했듯이 계층형 캐시 구조를 가지는 멀티 코어 아키텍처의 경우 메모리를 거치지 않고도 캐시 간 일관성 유지가 가능하므로 Owned 상태를 도입함으로써 메모리 접근 횟수를 낮출 수 있게 된다.

Owned 상태를 도입하는 경우 Shared 상태에서 메모리 일관성을 보장할 수 없다. Modified 상태의 캐시 데이터를 Shared Read하는 경우 해당 캐시는 Owned 상태가 되고, 다른 캐시는 Shared 상태가 될 것이다. 이때 Owned 상태는 메모리에 내용을 쓰지 않고 캐시 간 데이터를 공유하므로 Shared 상태에 있더라도 메모리 일관성이 유지되지 않는다. 반면 Exclusive 상태의 데이터를 Shared Read 했다면 데이터의 변동이 없었으므로 메모리 일관성이 유지된다.


'CS > 컴퓨터구조' 카테고리의 다른 글
| [컴퓨터구조] Parallel Processing(3) (0) | 2022.12.07 |
|---|---|
| [컴퓨터구조] Parallel Processing(2) (0) | 2022.12.05 |
| [컴퓨터구조] ILP & superscalar processor(2) (0) | 2022.11.28 |
| [컴퓨터구조] ILP & superscalar processor(1) (0) | 2022.11.23 |
| [컴퓨터구조] RISC (1) | 2022.11.22 |



