알고리즘
특정 문제를 풀거나 계산을 수행하는 데 사용되는 잘 정의된 명령의 유한 절차로, 어떠한 문제에 대한 해결 절차를 체계적으로 나타낸 후, 해당 절차에 따라 어떤 입력을 어떤 출력으로 변환하는 일련의 계산과정을 의미한다.
알고리즘의 대상이 되는 문제는 입력 및 출력의 형태로 요구조건을 나타낼 수 있어야 한다.
- ex) 도서관의 책을 ISBN에 따라 정렬하세요.
- 문제 : ISBN에 따른 도서관 책 정렬
- 입력 : 도서관의 책 & ISBN
- 출력 : 정렬된 책 리스트
알고리즘이 가져야 할 특성
- 명확성 : 최대한 이해하기 쉽고 간명하게 서술해야 한다.
- 명확하게 나타낼 수만 있다면 알고리즘을 나타내는 수단은 상관없음.
- 효율성 : 동일 문제 해결에 있어 최대한 시·공간적으로 효율적이어야 한다.
- ex ) for 문을 이용한 1~100 덧셈 vs 100·(100+1) / 2
알고리즘 기술 방법
기본적으로 알고리즘은 다수의 사람들이 알아보기 쉽다면 어떠한 형식을 사용하더라도 큰 상관이 없다. 여기서는 그중 몇가지 알고리즘 기술 방법에 대해 설명한다. 각 방법을 최대값 찾기 알고리즘을 통해 비교해보자.
- 자연어 표현 : 일상적으로 사용하는 자연어를 이용하여 알고리즘을 표현한다.
- 장점 : 자연어를 사용하므로, 대다수 사람들 입장에서 가장 읽기 편하다.
- 단점 : 알고리즘이 모호하게 이해될 수 있다.
# 최대값 찾기 알고리즘.
1. 첫번째 값을 tmp에 저장한다.
2. 현재 배열의 값과 다음 배열의 값을 비교한다.
3. 반복해서 다음 배열과, 그 다음 배열의 값을 비교한다. 비교는 배열이 끝날 때 멈춘다.
4. 만약 현재 배열 요소보다 idx+1 배열요소가 더 크면, tmp에 idx+1 배열요소를 저장한다.
5. 배열 탐색이 끝났을 때, tmp에 저장된 값이 최대값이다.- 흐름도(flow chart) 표현 : 흐름도를 이용하여 알고리즘의 흐름을 시각적으로 표현한다.
- 장점 : 시각적으로 표현되므로, 이해하기 쉽다.
- 단점 : 알고리즘이 복잡해짐에 따라 흐름도도 함께 복잡해지며, 플로우차트 시간에 많은 시간을 소모해야 할 수도 있다. (단 이 단점은 자동화 툴이 많이 등장함에 따라 큰 의미가 없을 수도 있다.)
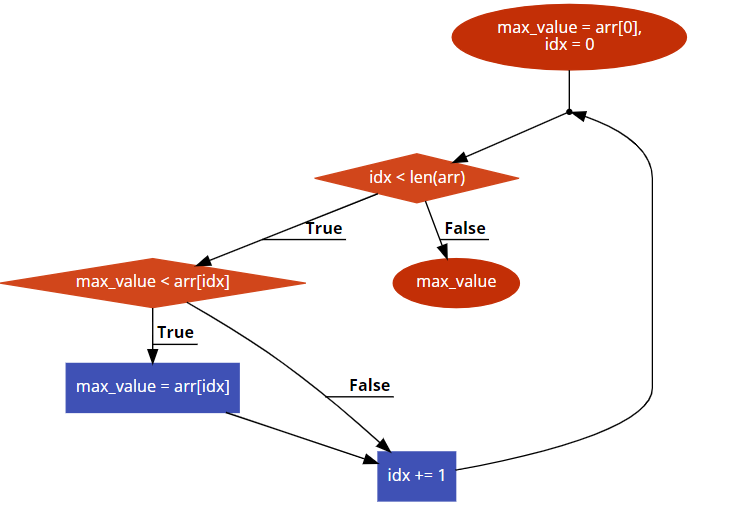
- 프로그래밍 언어로 표현 : 통상적으로 사용하는 프로그래밍 언어를 이용하여 알고리즘을 나타낸다.
- 장점 : 내용이 가장 정확하다.
- 단점 : 알고리즘을 이해하는데 있어 구현의 세부사항이 코드에 존재하므로, 알고리즘의 핵심이 무엇인지 파악하는데 오히려 방해될 수 있다. 정적 타입의 언어일수록 이러한 특성이 커지는 것 같다.
ex) 알고리즘에는 타입 정보, 동적 할당 등의 정보는 전혀 궁금한 사항이 아니지만, 코드를 이용하여 알고리즘을 표현하는데는 포함된다.
경우에 따라 특정 언어 자체가 장벽이 알고리즘 이해에 있어 장벽으로 작용하기도 한다.
def findmax(arr: list[any]):
max_value = arr[0]
idx = 0
while idx < len(arr):
if max_value < arr[idx]:
max_value = arr[idx]
idx+=1
return max_value- 유사 코드(pseudo code) 로 표현 : 프로그래밍 언어와 유사하지만, 세부 표현을 생략 혹은 추상화하여 표현한다. 사람마다 표현 방식은 다를 수 있으며, 변수와 같은 요소는 보통 선언 없이 사용한다.
- 장점 : 세세한 내용을 추상화하여 구현과 같은 세부 문제를 감춰 핵심에 집중할 수 있다. 핵심을 이해하기 쉽다.
- 단점 : 사람마다 표현법이 다를 수 있어, 이 방법 역시도 경우에 따라 오해를 일으킬 수 있다.
function findmax
input arr : list
max_value = arr[0]
for elem in arr :
if max_value < elem:
max_value = elem
return max_value
# 파이썬 언어와 유사하게 작성된 유사 코드알고리즘 평가 기준
- 정당성(Accuracy) : 모든 입력에 대해 올바른 출력을 내며 종료되는 경우, 알고리즘이 정당하다고 한다.
- 모든 입력에 대해 정확한 값이 보장되지는 않거나, 종료되지 않는 경우(무한 루프 등)에는 정당하지 않다.
- 효율성(Efficiency) : 한정된 시·공간적 자원 (time, space)에 대한 비용을 적게 사용하는 경우, 알고리즘은 효율적이다.
알고리즘 효율성 평가 방법
일반적인 함수에 대해 입력의 크기가 충분히 큰 경우, 최대차항을 제외한 값의 비중은 극도로 작아진다. 따라서, 해당 알고리즘의 효율성을 알고리즘의 최대차항에 비례하는 것으로 대략 표기할 수 있다.
예시) x^2 + xlog(x) 연산을 10, 50, 100, 500, 1000 에 대해서 수행한다.
from math import log10
from typing import Union
def calculate(numbers: Union[list[int], list[float]]):
# calculate x^2 + x*logx by value 10, 50, 100, 500, 1000
def func1(x): return x**2
def func2(x): return x * log10(x)
for x in numbers:
x2 = func1(x)
xlogx = func2(x)
result = x2 + xlogx
print('number : ', x)
print(f'result : {result}')
print(f'ratio of x^2 : {x2/result * 100:.3f} %')
print(f'ratio of xlogx : {xlogx/result * 100:.3f} %')
if __name__ == '__main__' :
numbers = [10, 50, 100, 500, 1000]
calculate(numbers)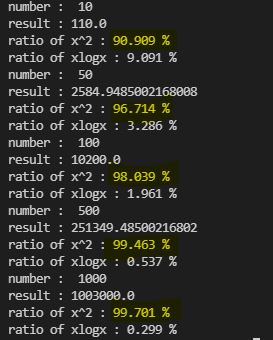
위 결과에서 볼 수 있듯이, n의 숫자가 충분히 커짐에 따라 알고리즘 내에서 최대차항의 비율은 극도로 높아진다. 따라서 최대차항 이외의 값이나 단순 상수는 입력의 크기 증가에 따라 충분히 무시할 수 있는 수준이 된다.
따라서 알고리즘의 효율성은 보통 대략적 / 점근적으로 표현한다.
- Big-O 표기법 : 연산 횟수를 대략적으로 표기하는 것으로, 함수의 상한을 의미한다.
알고리즘은 worst-case 에서도 동작해야 하는 특성상 최악의 경우가 가장 중요한데, 함수의 상한이 최악의 상황을 의미하므로, Big-O 표기법이 알고리즘의 효율을 나타낼 때 가장 많이 사용된다.
-> O(g(n)) = { f(n) | ∃c > 0, n0 ≥ 0 s.t.∀n ≥ n0, f(n) ≤cg(n)} - Big-Ω 표기법 : 함수의 하한을 표기하는 방법.
-> Ω(g(n)) = { f(n) | ∃c > 0, n0 ≥ 0 s.t.∀n ≥ n0, cg(n)≤f(n) } - Big-Θ 표기법 : 함수의 상한 및 하한을 나타내며, 함수가 대략 어느정도 수준에 묶여있는지에 대한 정보를 제공한다.
가장 좋은 방법이기는 하나, 상한 및 하한을 둘다 구해야하는 불편함이 있어 Big-O 표기법에 비해 사용되지 않는다.
-> Θ(g(n)) = { f(n) | ∃c1, c2 > 0, n0 ≥ 0 s.t.∀n ≥ n0, c1g(n) ≤ f(n) ≤ c2g(n)}
- small-o 표기법 : Big-O 표기법에서 등호를 제거한 알고리즘 측정 방식.
-> o(g(n)) = { f(n) | ∃c > 0, n0 ≥ 0 s.t.∀n ≥ n0, f(n) < cg(n)} - small-𝜔 표기법 : Big-Ω 표기법에서 등호를 제거한 알고리즘 측정 방식.
-> 𝜔(g(n)) = { f(n) | ∃c > 0, n0 ≥ 0 s.t.∀n ≥ n0, cg(n) < f(n) }

'CS > 알고리즘&문제풀이' 카테고리의 다른 글
| [python] 파이썬 re 모듈 동작 방식 (1) | 2023.03.13 |
|---|---|
| 최대 공약수, 최소 공배수 (0) | 2023.03.03 |
| [알고리즘] 분포기반 정렬 (0) | 2022.04.11 |
| [알고리즘] 비교 기반 알고리즘 (0) | 2022.03.29 |
| [알고리즘] 정렬 00 : 정렬 개요 (0) | 2022.03.14 |


