현재 글은 이 글과 이어진다.
Error Correction
메모리와 같은 반도체 장치들은 에러가 발생할 가능성을 가진다. 전송 과정에서 전자가 손실되는 경우 해당 에러를 수정하거나 최소한 에러가 발생했다는 사실을 알려야만 데이터를 유효한 상태로 유지할 수 있다.
(하드웨어 공정에서 불순물로 결함이 발생하는 경우 최소한 어디서 결함이 발생하는지를 알아야 해당 영역의 메모리를 우회, 다른 영역에 연결하여 메모리 폐기율을 낮출 수 있을 것이다.)
에러는 2가지로 나뉜다.
- Hardware Failure:
영구적으로 발생하는 물리적 결함으로, 과전류 등 사용 환경에서의 문제, 제작 공정에서 발생한 결함 및 여러 번의 WRITE 동작에 의한 마모에 의해 발생할 수 있다.
메모리 셀이 특정한 값으로 고정되고 바뀌지 않는 현상이 일어난다. 일반적으로 하드웨어적 결함에 의한 에러는 고칠 수 없는 경우가 많으므로 장비 자체를 교체하게 된다. - soft error: 하나 이상의 메모리 셀에서 순간적으로 발생하는 에러로, 해당 에러가 계속 유지되는 것은 아니다. 전원 공급 문제, 방사능 노출 등이 원인으로 꼽힌다.
에러 수정 코드(Error Correction Code)
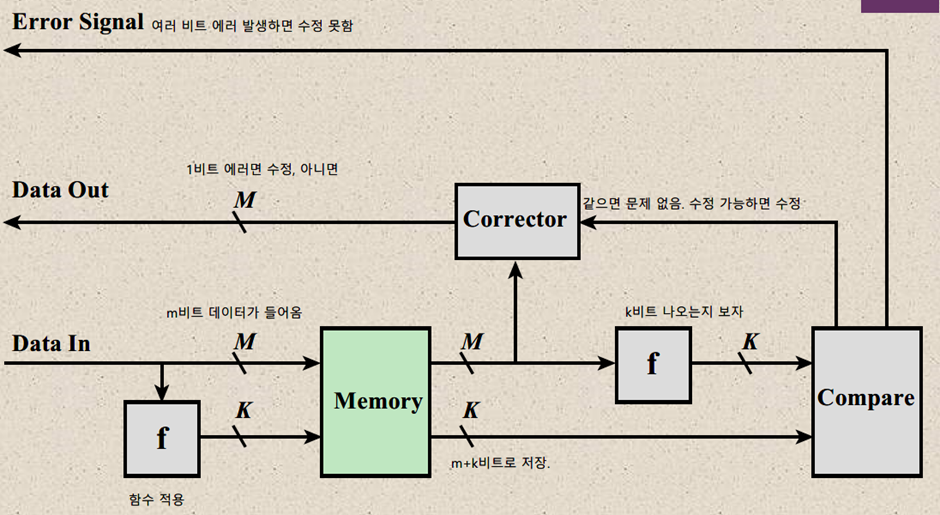
에러를 수정하거나 식별하기 위해서는 에러가 발생했는지 여부를 식별할 방법이 있어야 하는데, 이 대목에서 코드가 필요하다. 에러수정 코드는 저장 시점의 데이터와 읽은 시점의 데이터를 비교하기 위해 데이터와 함께 저장하는 코드로, 특정한 함수를 거쳐 생성된다. 저장된 데이터를 사용해야 하는 경우 데이터 및 코드를 함께 읽는다. 데이터에 있는 에러는 새로 생성한 코드와 기존 코드를 비교하는 과정을 통해 식별한다. 만약 데이터에 에러가 발생하지 않았다면 최초 시점에 만들어진 코드는 새로 만들어진 코드와 동일할 것이다. 이 경우 두 코드를 XOR 연산하여 syndrome word을 구하면 0이 될 것이다. 반면 값이 다르다면 syndrome word 중 어딘가는 1이 있게 된다.
에러는 크게 3가지 상황으로 나눌 수 있다.
- 에러가 발생하지 않은 경우
- 에러가 발생했고, 수정할 수 있는 경우
- 에러가 발생했고, 수정할 수 없는 경우
해밍 코드
에러 수정 코드의 예시로 해밍 코드가 있다. 해밍 코드는 데이터를 전송할 때 1비트의 에러를 정정할 수 있는 오류 정정 코드로, 패리티 비트를 통해 식별한 위치의 오류를 수정할 때 사용된다

위 그림은 데이터가 4비트, 코드가 3비트 크기를 가질 때 1비트 에러가 발생한 상황을 나타낸다.
초기 데이터가 1110인 경우 3비트 단위로 XOR 연산을 수행하여 ABC = 100이라는 코드를 얻을 수 있다. 만약 데이터 전송 중 손실이 발생하여 1100이 되었다고 가정하자. 이때 생성되는 데이터에 대한 해밍 코드는 001로, 기존에 가진 100과 다르므로 에러가 발생했음을 알 수 있다. 이때 110을 만들기 위한 1비트 에러의 위치는 자명하므로 식별 및 수정을 동시에 수행할 수 있다

위 그림은 데이터가 4비트, 코드가 3비트 크기를 가질 때 2비트 에러가 발생한 상황을 나타낸다.
초기 데이터는 1110으로, ABC = 100의 해밍 코드를 가졌다. 이때 어떤 이유로 두 비트에 에러가 발생하여 1000이 된다. 이 경우 해밍 코드는 110이 된다. 문제는 현재 발생한 에러가 1비트 에러인지, 아니면 2비트 에러인지 명확하게 식별할 수 없는데 있다. 1비트 에러라고 생각하는 경우 패리티 비트 자체에 에러가 생겼다고 볼 수 있고, 2비트 에러라고 생각하는 경우 두 개 데이터 비트에 에러가 발생했다고 생각할 수 있다. 두가지 가능성이 있을 때 둘 중 하나를 도박하듯이 선택하는 것은 좋은 방법이 아니다. 현재 에러가 1비트 에러인지, 아니면 2비트 에러인지 식별하기 위해 전체 패리티 비트를 XOR한 하나의 추가적인 패리티 비트를 둘 수 있다.
SEC-DED 해밍 코드(single error correction, double error detection)
위에서 보인 방식에서는 1비트 에러와 2비트 에러 상황을 구분할 수 없었다. SEC-DED 방식에서는 전체 패리티에 대한 검증을 위해 XOR 결과 패리티 비트를 추가적으로 둬서 이 문제를 해결한다.

위 그림은 에러가 발생했을 때 전체에 대한 패리티 비트가 있을 때 double error을 식별하는 과정을 보인다. (a)의 데이터는 (b)의 패리티 비트를 가진다. 이때 (c)의 형태로 2비트 에러가 발생했다고 생각해보자. 전체에 대한 패리티 비트가 없는 경우 가지고 있는 ABC = 110 정보를 이용하여 데이터 비트를 수정하므로 (d), (e)처럼 0011을 만들었을 것이다. 그러나 이 경우 전체 패리티 비트가 0이 되어야 한다. 따라서 현재 상황을 2비트 에러로 식별할 수 있다. Extra parity bit와 syndrome word에 따른 에러 판단은 다음과 같다.
| Syndrome word == 0 | Syndrome word != 0 | |
| Parity 비트가 정상 | good | 2bit error ( detection ) |
| Parity 비트가 비정상 | Parity 비트 자체에 에러가 생김 | 1bit error ( correctable) |
사실 4비트 데이터의 정확도를 판단하기 위해 4비트 패리티 비트를 사용해야 하는 상황은 효율적이라고 말하기 힘들다. 다행히도 데이터 비트의 크기가 커짐에 따라 전체 워드에서 패리티 비트가 차지하는 비율은 점점 작아진다.
구체적으로는 다음 공식을 만족한다.

한 워드는 M+K의 크기를 가진다. 이때 k비트는 2k 개의 값을 식별할 수 있다. 2k는 전체 에러 및 에러가 발생하지 않는 상황(1)을 식별할 수 있어야 하므로 M+K+1 보는 크거나 같아야 한다는 논리가 성립하며, 위 공식이 도출된다.

실제 상황에서 에러가 발생했는지 여부를 벤 다이어그램을 통해 판단할 수는 없다. 구체적인 동작 방식은 다음과 같다.

위 그림은 데이터 비트가 8, 패리티 비트가 4인 경우를 나타낸다. 패리티 비트는 전체 비트 중 1비트만이 0인 0001, 0010, 0100, 1000에 존재하고, 나머지 비트는 에러가 발생한 데이터 비트의 위치를 표현한다.
패리티 비트들의 값은 자신에 대응되는 주소 위치의 값이 1인 데이터들의 XOR연산 결과다. 예를 들어 C8은 1000 주소를 가지며, 2^3 자리의 비트가 1로 지정된 데이터 비트는 D5, D6, D7, D8이므로 C8의 값은 D5 ⨁ D6 ⨁ D7 ⨁ D8이 된다. 나머지 값들도 아래와 같이 나타난다.

패리티 비트를 위와 같이 관리하는 경우 이전 해밍 코드와 새로 생성된 해밍 코드를 XOR 연산하여 비트 에러가 발생한 위치를 바로 식별할 수 있다는 장점이 있다. 아래 표를 보자.

현재 표는 D6 자리에서 비트 에러가 발생한 모습을 보여주고 있다. 저장된 데이터의 해밍 코드는 0111, 에러로 인해 발생한 해밍 코드는 0001일 때 0111 ⨁ 0001 = 0110이다. 이 값은 비트 에러가 발생한 위치와 동일하다.
DDR DRAM
고성능 프로세스에서 발생하는 병목 현상은 내부 메인 메모리에 의한 경우가 많다. 그러나 메모리의 성능을 높이겠다고 CMOS보다 좋은 반도체를 찾는 등의 모험은 시간과 자본 측면에서 매우 비효율적이며 달성할 수 있다는 보장도 없다. 따라서 최근에는 메인 메모리 성능을 높이기 위해 DRAM 아키텍처를 향상하는 여러 가지 방법들이 개발되고 있다고 한다.
SDRAM(Synchronous DRAM)
프로세서와의 데이터 교환을 외부 클럭 신호에 동기화하는 방식의 DRAM으로, wait state 없이 프로세스/메모리 버스를 최대한 사용할 수 있다고 한다. 프로세서 혹은 마스터가 instruction 및 address 정보를 발행하면 정해진 사이클 뒤에 이에 반응하여 데이터를 fetch 한다.
사실 내 입장에서는 asynchronous DRAM을 사용할 일이 없었기 때문에 SDRAM이 기본 옵션이었으며, 마노 책에서 배우는 메인 메모리 동작 방식도 클럭 기반이라 감이 잘 오지는 않았다. 과거에는 DRAM이 비동기적으로 운영되었다. CPU가 메모리에 데이터를 요청하면 메모리는 일련의 작업을 통해 대응되는 데이터를 제공하는데, 문제는 CPU 입장에서 메모리가 해당 데이터를 언제 돌려줄지 알 방법이 없다는 것이다. 따라서 CPU는 메모리가 언젠가 데이터를 제공할 것이라는 불확실한 믿음 아래에서 동작하므로 안정성이 떨어지는 단점이 있었다고 한다. 가령 메모리에 데이터를 2개 요청한다고 생각해보자. 첫 데이터를 요청하고 이를 반환하기 이전에 두 번째 데이터를 요청하는 경우 비동기 방식에서는 기존 요청에 영향을 줄 수 있으므로 정상적인 데이터를 받기 위해서 더 긴 시간을 대기하고, 그 이후에 새로운 데이터를 요청해야만 한다. 반면 SDRAM에서는 어느 사이클에 데이터가 들어올지 알고 있기 때문에 정해진 사이클에 따라 요청하고 응답할 수 있다.
https://www.technipages.com/review/what-is-asynchronous-dram

DDR(Double Data Rate) SDRAM
DDR은 한 클럭에 2개의 데이터를 읽는 방법을 뜻한다. 클럭은 1과 0을 반복하면서 구분된다.

이때 클럭은 1과 0을 기준으로 쪼갤 수 있다. 올라가는 클럭인 1을 기준에서는 T0, T1, T2을 볼 수 있고, 내려가는 클럭인 0 기준에서는 T0’, T1’ 및 T2’을 볼 수 있다. 이렇게 하나의 클럭을 2개의 관점으로 쪼개고, 각 관점을 기준으로 동작하는 장치를 따로 두면 한 클럭 내에서도 데이터를 2번 읽어올 수 있게 된다. 높은 클럭을 이용하여 데이터 전송률을 높이는 방법으로, 버퍼링이 요구될 수 있다.
DDR SDRAM의 성능 단위는 PC~ 형식을 띤다.예를 들어 DDR4 25600이라고 하면 현재 메인 메모리는 DDR 4세대이며 초당 25600MB을 계산할 수 있다는 의미가 된다. 공식은 다음과 같다.
전송 단위 * 한 클럭에 전송하는 데이터 개수 * 클럭 속도
만약 전송 단위가 64비트, 한 클럭에 2개 데이터를 전송할 수 있으며 100 MHz의 클럭 속도를 가지는 경우 8(byte) * 2 * 100 = PC1600 = 1600MB/s가 된다.

Prefetch buffer
초기 버전의 DDR은 2비트 prefetch buffer을 사용했다. Prefetch buffer은 SDRAM 내부에 위치한 메모리 캐시로, SDRAM이 비트를 최대한 빨리 사전 배치할 수 있도록 만들어준다. 행 주소를 기반으로 한 번에 많이 가져온 버퍼 속 데이터들은 개별적인 열 주소에 대한 요청(CAS) 없이 접근할 수 있어 bandwidth을 높이는데 도움이 된다.
단, 연속된 데이터가 아니라 특정한 워드 하나만 읽는 경우에는 데이터를 많이 가져오는 행위가 큰 의미가 없을 수 있다. 이러한 이유로 DDR4에서는 버퍼의 크기는 그대로 두고 bank group을 도입하여parallel 하게 데이터를 읽어온다고 한다.


Multichannel DDR
여러 개의 채널을 통해 메모리를 연결하여 사용하는 방법이다. 각 채널에 연결된 메모리 모듈들은 뱅크에 대응된다. 이론적으로 채널의 개수와 성능 향상은 비례한다.
https://en.wikipedia.org/wiki/Multi-channel_memory_architecture#Dual-channel_architecture

eDRAM(embedded DRAM)
프로세서와 동일한 칩 상에 존재하는 DRAM으로, 프로세서가 수행하는 애플리케이션에 최적화된 구조(Application-Specific Integrated Circuit, ASIC)를 가진다.
On-chip SRAM과 Off-chip DRAM 사이, 즉 칩 내부의 캐시와 메인 메모리 사이에 존재한다. 칩 내부에 DRAM이 있는 경우 QPI 등을 통해 물리적으로 직접 연결되기 때문에 칩 외부에 있는 것보다는 성능이 좋다. SRAM의 성능 및 DRAM의 가격 및 용량의 장점을 적절하게 절충한 구조다.

최근 사회에서 요구하는 애플리케이션이나 대형 시스템들은 소위 빅데이터를 처리하는 경우가 많다. 이에 따라 과거 spetial locality가 특정한 소수 코드 영역에서만 집중적으로 나타났던 것과는 달리 넓은 영역에 퍼진 형태로 나타난다. 이에 따라 메모리가 다음에 레퍼런스 할 확률이 높은 영역의 범위가 증가하여 캐시의 용량이 커질 필요가 있었다. 그러나 SRAM 기반 캐시는 가격이 상당히 높기 때문에 쉽게 추가할 수 없다. 대신 DRAM을 칩 내부에 두고 캐시처럼 사용하는 eDRAM 방식이 대두되었다.
eDRAM은 언급했듯이 캐시와 메인 메모리 사이에 존재하며, 여러 성질들 역시 둘의 중간 정도에 있다.


플래시 메모리
플래시 메모리는 EPROM과 EEPROM의 가격 및 기능 면에서 중간 위치에 있는 메모리다. EEPROM은 EPROM과는 달리 데이터를 바이트 단위로 지우고 쓸 수 있다는 장점이 있으나 가격이 높아 쉽게 사용할 수 없었다. 플래시 메모리는 EEPROM과는 달리 블록 단위로 내용을 지워야 한다는 단점이 존재하기는 하지만 가격이 EEPROM에 비해 저렴하다. 각 블록은 여러 개의 페이지로 구성되며 데이터는 페이지 단위로 읽고 쓸 수 있다. 한 비트에 트랜지스터가 하나만 사용되기 때문에 EPROM의 저렴한 가격도 챙길 수 있다.
플래시 메모리는 DRAM과 많은 부분에서 구조상의 커다란 차이가 있다.
- 읽기 동작이 순차적으로 수행된다. 페이지에 접근할 때는 random access을 이용하지만, 페이지 내에서 특정 데이터를 찾을 때는 앞에서부터 순차적으로 읽어 나가야 한다. Random access에는 약 25us가 소요되며, 읽는 속도는 40 MiB/s 정도가 된다. DDR4 RAM의 Random access 시간이 40ns이고 row을 읽는 속도가 4.8 GiB/s 정도인 것을 고려하면 대략 100배 이상 읽기 성능이 떨어진다. 반면 하드 디스크에 비하면 약 500배 이상 빠르다.
- 플래시 메모리는 데이터를 덮어쓸 수 없다. 데이터를 쓰기 위해서는 반드시 해당 영역을 초기화해야 하며, 이를 위해 erase 동작이 필요하다. 데이터는 블록 단위로 전부 지워야 하며, 지울 수 있는 최대 횟수가 정해져 있다. 이로 인해 쓰기 동작은 SDRAM에 비해 1500배 정도 느리며, 하드 디스크에 비해서는 15배 정도 빠르다. 쓰기 동작은 하드 디스크에 가깝다.
- 플래시 메모리의 정보는 한번 작성되면 전원이 없더라도 변하지 않는다(nonvolatile). DRAM과 달리 refresh가 필요 없기 때문에 대기 상태에서 발생하는 전력 소모가 매우 적다.
- 플래시 메모리는 쓸 수 있는 횟수가 정해져 있다. 따라서 플래시 메모리에 오류가 발생하지 않기 위해서는 전체 영역을 골고루 사용함으로써 uniform distribution을 만족해야 한다. 이처럼 블록 당 write 및 erase 횟수를 균일하게 만드는 방식을 write leveling이라고 한다.
- NAND 플래시 메모리의 경우 디스크보다는 비싸지만 SDRAM에 비하면 매우 싸다.
플래시 메모리의 원리
플래시 메모리는 MOSFET이라는 반도체를 기반으로 동작한다.


위 그림은 source와 drain이 n+로 도핑된 NMOS 구조를 보여준다. 기본 상태에서는 source와 drain 사이에 전류가 통하지 않는다. 이때 gate에 (+) 전압을 일정 이상 가하면 P-substrate 상에 있는 (-) 전자가 위에 붙는다. 이 상황에서 source와 drain 사이에 전압 차이가 발생하면 전류가 흐른다고 한다. 이게 MOSFET의 기본 동작이다.
플래시 메모리에서는 MOSFET의 게이트에 floating gate라는 영역을 추가로 둔다. 기본 상태에서는 Floating Gate에 전자가 없다. 이 상태는 컴퓨터 기준 “1”로 표현된다. 기존과 동일하게 일정 이상의 전압을 Control Gate에 가하면 전자가 위쪽으로 모인다. 이때 기존보다 더 강한 전압을 주면 신기하게도 전자가 막을 뚫고 Floating Gate 안으로 들어온다(양자 터널링 현상을 활용한 것이라고 한다). 이 상황을 컴퓨터는 “0”으로 인식한다. Erase 동작은 반대로 body에 강한 전압을 가해서 floating gate로부터 전자를 가져온다.
NAND / NOR 플래시 메모리
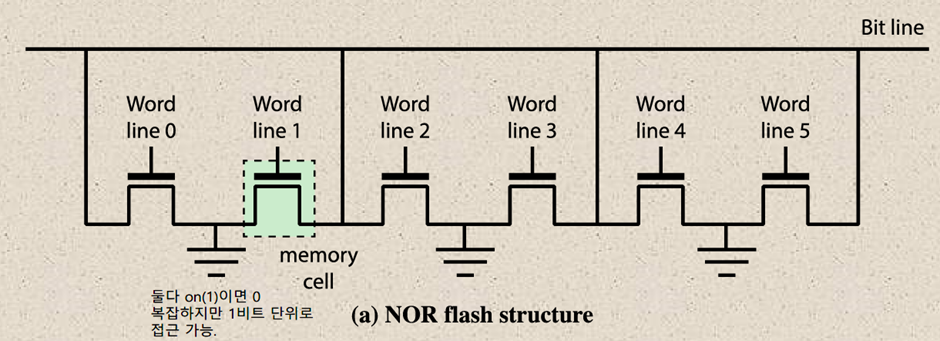
NOR 플래시는 두 라인이 모두 on일 때 0을 의미하는데, 이게 NOR 회로와 유사해서 이름이 붙었다. 각 주소 라인이 셀 단위로 설치되어 random access가 가능하기 때문에 접근 속도가 일정하므로 코드를 NOR에서 읽어 실행할 수 있다. 다만 회로가 복잡해지는 단점이 있다.

NAND 플래시는 반대로 NAND 회로와 비슷하게 동작한다고 해서 이름이 붙었다. 주소 라인이 직렬적으로 설치되어 있어 특정 셀의 값을 알아내기 위해서 직렬로 읽어 나가야 하는 문제가 있다. 대신 NOR보다 회로가 많이 간단해서 집적도를 높일 수 있다는 장점이 있다.
| NAND: random page access(10μ) + serial page access(50ns/byte) Block Erase(2msec) Page Program(200 μsec) 읽기 속도가 느리지만 지우기 속도는 빠른 편이다. 순차 접근이 필요하므로 프로그램을 실행하기에 좋은 조건이 아니다. 대신 회로가 간단하여 집적도가 높기 때문에 SSD에 사용된다. NOR: Word read(random) Block Erase(0.5sec) Word program(10μ) 모든 주소를 대상으로 random access가 가능하므로 읽기 속도가 빠르다. 반면 지우기 속도가 치명적으로 느리다는 문제가 있다. Random access을 기반으로 프로그램을 메모리 등에 옮기지 않고 직접 실행할 수 있다. XIP(execute in place) 메모리에 사용된다. |


Write endurance & wear leveling
플래시 메모리는 읽고 쓰는 횟수가 한정되어 있으므로 쓰는 동작을 최소한으로 줄이고, 메모리 전체적으로 고르게 쓰도록 만들어 고장을 줄여야 한다(wear leveling).
wear leveling의 타입은 다음과 같다.
| 이름 | 설명 |
| No Wear Leveling | 영구적인 물리적 주소 기반으로 데이터에 접근해서 지우고 읽고 쓰는 방식. 데이터의 위치가 고정되어 있으므로 지우고 쓰는데 시간이 오래 걸리며, 셀의 일부만 사용되므로 마모가 편중된다. |
| Dynamic Wear Leveling | 사용 가능한 공간만을 대상으로 지우기 횟수가 적은 블록에 먼저 쓰기 작업을 수행한다. |
| Static Wear Leveling | 모든 블록(데이터를 쓴 블록 및 빈 블록)을 대상으로 지우기 횟수가 적은 블록에서 다른 블록으로 데이터를 이동시켜 해당 블록에 먼저 쓰기 작업을 수행한다. 변하지 않는 데이터가 있는 블록의 경우 상대적으로 삭제 횟수가 적을 수 있는데, 이러한 데이터를 주기적으로 옮김으로써 uniform distribution을 만족시킨다. |
| Global Wear Leveling | 단일 칩에 대해 적용되는 Static Wear Leveling과는 달리 더 넓은 범위의, 전체 장치에 대해 지우기 횟수가 작은 블록을 관리하여 선별적으로 쓰기 작업을 진행한다. |
위 내용만 보면 Static Wear Leveling이 Dynamic Wear Leveling에 비해 플래시 메모리의 수명이 길기 때문에 더 많이 사용할 것으로 보인다. 그러나 Static Wear Leveling의 경우 모든 블록을 고려하는 과정에서 상대적으로 속도가 느려지는 단점이 존재하며, 저장장치의 용량이 큰 경우 빈 블록이 많아 지우기 횟수가 상대적으로 적어지는 효과가 있어 수명이 크게 단축되지 않으므로 Dynamic Wear Leveling을 많이 채택한다고 한다.
한 셀에 저장할 수 있는 비트 수는 임계 전압 및 전하량을 어떻게 다루는 가에 따라 달라진다. 셀 하나 당 1비트를 표현하는 경우 0, 1에 대한 전하 조건만 존재하면 된다. 반면 2비트를 표현하는 경우 00, 01, 10, 11에 대한 전하량을 구분할 수 있어야 한다. 구분되는 전하량 비율 사이마다 각 상태를 구분하기 위한 완충 구간이 존재하는데, 이 구간에 해당하는 전하를 보유한 경우 셀이 고장 났다고 판단한다. 따라서 셀 당 표현 가능한 비트 수가 많아질수록 에러에 민감해지고 셀의 내구성이 떨어진다. 예를 들어 SLC에서 TLC로 갈수록 한 셀 당 표현할 수 있는 비트의 수는 1, 2, 3으로 증가하지만 WRITE 횟수는 100k, 10k, 1k로 크게 감소한다.
플래시 메모리에 대한 설명:
- https://news.skhynix.co.kr/post/principle-of-nand-flash-memory
- https://www.sedaily.com/NewsView/22VGVKXH0B
미래의 메모리들
- STT-RAM: 마그네틱 기반의 램으로, 비휘발성, 빠른 R/W 속도(<10ns), 대기 전력 최소 등의 장점이 있다고 한다.
- Phase-change RAM(PCRAM): 데이터를 저장하는 물질이 결정형-비결정형의 페이즈를 바꾸는 방식으로 데이터를 저장한다고 한다. DRAM과 플래시 메모리 사이의 성능을 보인다고...
- ReRAM: 전하의 충전 대신 물질의 저항을 바꾸는 방식으로 정보를 저장하는 RAM.
이러한 메모리 중에 가장 근미래에 사용될 수 있는건 PCRAM이라고 한다.
'CS > 컴퓨터구조' 카테고리의 다른 글
| [컴퓨터구조] External Memory(2) (0) | 2022.10.31 |
|---|---|
| [컴퓨터구조] External Memory(1) (0) | 2022.10.19 |
| [컴퓨터구조] Internal Memory(1) (0) | 2022.10.12 |
| [컴퓨터구조] 캐시(3) (0) | 2022.10.10 |
| [컴퓨터구조] 캐시(2) (1) | 2022.10.05 |



