현재 글은 컴퓨터 구조와 아키텍처 서적 및 대학에서 들은 강의를 기반으로 한다.
어떤 물건을 구매하더라도 최소한 품질과 가격만은 필수적으로 고려하게 된다. 이때 가장 이상적인 상황은 품질 높은 제품이 가격까지 싼 경우이다. 하지만 대부분의 경우 품질과 가격은 트레이드오프 관계에 있으며, 이는 메모리에도 동일하게 적용된다. DRAM 기반의 메모리는 가격이 저렴한 편이지만, CPU의 빠른 연산을 온전히 뒷받침할 수 있을 정도로 속도가 빠르지는 않다. 반대로 SRAM 기반의 메모리는 기계적으로 동작하여 속도가 매우 빠르기는 하나, DRAM 기반 메모리 마냥 용량을 늘리기에는 비용이 너무 많이 든다. 결국 비용 문제로 볼 수 있다.
따라서 현대 컴퓨터는 CPU와 DRAM 기반 메인 메모리 사이에 속도는 빠르지만 용량은 그보다 적은 캐시 메모리를 두고 데이터를 계층적으로 찾도록 진화했다. CPU는 최상위 레벨의 캐시부터 시작하여 계층에 따라 차례대로 데이터를 요청하게 되며, 요청한 데이터가 있는 경우 해당 데이터를 이용한다. 캐시는 특정 데이터를 요청받게 되면 이와 관련된 데이터들이 미래에 사용될 것이라고 생각하고 미리 가져온다. 이를 통해 CPU가 근미래에 사용하는 데이터가 캐시에 있을 확률이 높아지므로, 하위 계층에 접근해야 하는 일이 줄어든다. 이와 같은 동작들은 상대적으로 속도가 느린 메인 메모리에 대한 접근 횟수를 최대한 줄이기 위한 노력이다.
Locality
컴퓨터 프로그램은 locality가 있는 것으로 알려져 있다. locality는 특정 위치의 데이터를 사용할 때, 해당 데이터와 함께 사용하는 데이터들이 시간적 또는 공간적으로 가까운 위치에 있음을 의미한다.
예를 들어 다음과 같은 코드를 생각해보자.
for(int i = 0; i < 100; i++)
{
arr[i] = i;
}위 for문은 i의 값에 따라 100번 반복된다. for문을 순회할 때마다 i 값에 접근해서 값을 대입해야 하므로 i는 가까운 시간 내에 자주 사용될 것이라고 판단할 수 있다. 즉, i는 시간적인 locality을 가진다. 배열 arr의 경우 for문을 순회할 때마다 인덱스를 하나씩 증가시키면서 값을 대입하고 있다. 배열은 구조 상 연속으로 저장되므로 가까운 데이터를 연속적으로 사용한다고 생각할 수 있다. 따라서 arr은 공간적인 locality을 가진다.
프로그램 안에는 반복 루프나 서브 루틴 등 특정 동작을 반복하는 경우가 많다. 이 경우 해당 코드에서 사용되는 instruction set이나 접근하는 데이터는 어느 정도 한정되어 있다. 이를 하나의 클러스터로 볼때, 프로그램 내에는 수많은 클러스터가 존재한다. 긴 시간을 두고 보면 프로그램이 수행하는 업무가 변하므로 사용하는 데이터가 계속 바뀌는 것처럼 보이지만, 이를 짧은 시간 단위로 잘라서 보면 결국 클러스터를 바꿔가면서 실행하는 모습으로 볼 수 있다.
로컬리티에 대한 가정
- 어떤 시간 구간에서 프로그램이 접근하는 메모리 영역은 전 구간에 대해 고르게 분포하지 않는다. 대신 유난히 많이 접근하는 구간이 존재한다.
- 시간이 지남에 따라 전체 메모리의 유닛에 대해 참조할 확률 분포는 천천히 변한다.
- 직전에 참조한 메모리의 내용은 다음에 참조할 메모리의 내용과 연관성이 높은데, 이는 시간 간격이 길수록 감소한다.
위 가정들은 앞에서 설명한 locality에 대한 성질과 일맥상통한다. 프로그램은 시간 및 공간적으로 가까운 데이터를 사용할 확률이 높으며, 데이터는 함께 사용되는 일종의 그룹을 가지고 있다.
로컬리티의 종류
- Temporal Locality : 시간적인 로컬리티
- 한번 접근한 정보는 가까운 미래에 다시 접근할 가능성이 높다.
- ex) iterative loop 등
- Spatial Locality : 공간적인 로컬리티
- 특정 데이터에 접근하면 다음 접근할 데이터는 주소 상 근처에 있을 확률이 높다.
- ex) 배열 등


메모리의 주요 특성
| 특성 | 종류 |
| 위치(Location) | Internal (프로세서 레지스터 등) External(CD 등) |
| 용량(Capacity) | Number of words Number of bytes |
| 전송 단위(Unit of Transfer) | Word Block |
| 접근 방법(Access Method) | Sequential Direct Random Associative |
| 성능(Performance) | Access Time Cycle Time Transfer rate |
| 물리적 종류(Physical Type) | Semiconductor Magnetic Optical Magneto-optical |
| 물리적 특성(Physical Characteristics) | Volatile / Nonvolatile Erasible / Nonerasible |
| 구조(Organization) | Memory modules |
데이터 유닛 접근 방식
- Sequential access
- Direct access
- Random access
- Associative
Sequential access
메모리는 record 라고 불리는 데이터 유닛으로 구성된다. 특정 데이터에 대한 주소가 따로 존재하지 않으므로 어떤 데이터를 찾으려면 앞에서부터 선형적으로 차근차근 찾아봐야 한다. 따라서 데이터가 저장된 위치에 따라 접근 시간이 다르다.
데이터에 대한 접근 시간이 천차만별이라는 단점이 있으나, 주소 기반이 아니므로 고정된 주소 길이에 구애받지 않으므로 메모리의 크기를 무한정 늘릴 수 있다는 장점이 있다.
Direct access
주소 기반으로 동작하지만 해당 주소에 대응되는 물리적 위치에 따라 접근 시간이 달라진다. 예를 들어 하드 디스크는 여러개의 판에 대해 일정 크기로 나뉘는 저장 단위인 섹터, 섹터가 위치하는 동심원 형태의 트랙, 각 판에서 트랙을 모은 실린더를 가진다.
이때 특정 데이터를 찾기 위해서는 헤드가 데이터가 위치한 실린더를 우선 찾아야 하고(seek time), 이후 원판을 돌려 실제 데이터가 저장된 섹터 위치로 이동해야 한다(rotational latency). 따라서 주소 기반으로 동작하더라도 현재 헤드가 가리키는 위치에서 가까운지 등에 따라 데이터에 접근하는데 걸리는 시간(Access time)이 달라질 수 있다.

Random access
고유한 주소 기반으로 동작하며, 주소에 대응되는 위치에 바로 접근할 수 있어 모든 데이터에 접근하는 시간이 동일하다. 메인 메모리나 캐시 메모리 등에 이용된다.
Associative
주소 대신 데이터가 가진 컨텐츠에 기반하여 데이터를 찾는 방식으로, 두가지 큰 특징이 있다.
- content addressable: 컨텐츠의 내용을 기반으로 대응되는 정보를 비교해서 찾을 수 있다.
- parellel search: 여러개의 저장소가 있을 때, 이들에 대해 동시에 찾을 수 있다.
일치 항목에 대해 원하는 비트 위치를 비교하되 모든 영역에 대해 동시에 수행 가능하다. 각 위치에는 고유한 주소 지정 매커니즘이 있고, 위치와 관계 없이 검색 시간이 동일하다.
Content Addressable Memory(CAM)
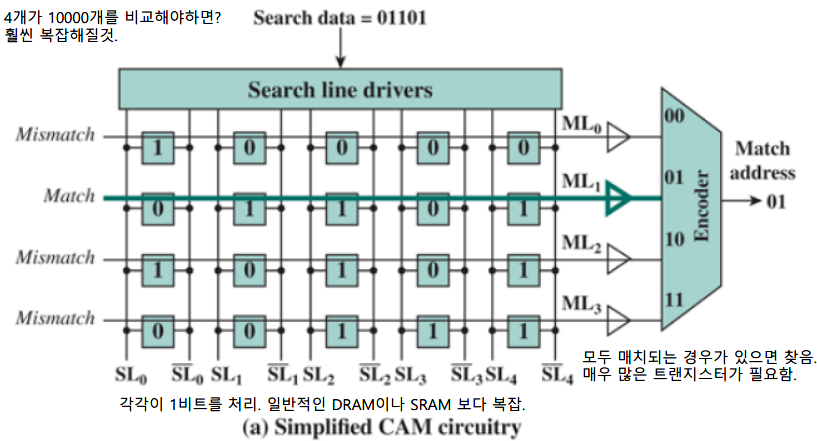

CAM은 Associative Memory의 일종으로, 외부에서 검색하고자 하는 데이터를 전달하면 내부에 저장된 데이터들을 단일 클럭 내에 검사하여 모두 매치되는 라인의 주소를 반환한다. 그림을 보면 모든 데이터들은 회로적으로 한번에 연결되어 동시에 매칭 여부를 알아낼 수 있다. 현재 컴퓨터에서는 연상 기반 캐시 메모리에 사용된다고 한다.
Performance
메모리의 성능을 비교할때는 다음 세가지 요소를 고려한다.
- Access Time(Latency)
- Memory Cycle Time
- Transfer Rate(Bandwidth)
Access Time(Latency)
Access Time은 특정 데이터에 접근할 때 걸리는 시간을 의미한다. Random Access Memory의 경우 어떤 위치에 접근하든지 동일한 시간을 요구하기 때문에 단순히 READ, WRITE에 소요되는 시간으로 정의한다. 반면 RAM이 아닌 하드 디스크와 같은 메모리는 데이터가 어디에 저장되어 있는지에 따라 해당 데이터에 접근하는데 걸리는 시간이 다르다. 따라서 해당 매체가 가진 Read/Write 매커니즘에 의해 정해진 위치로 이동하는데까지 걸리는 시간으로 정의한다.
Memory Cycle Time
Memory Cycle Time은 한번 메모리 엑세스가 진행되고 다음 엑세스가 진행될 수 있을때까지의 시간 간격을 의미한다.
컴퓨터는 전자기기이며, 실제로 물리법칙에 따라 동작한다. 따라서 회로에 전류를 흘려 넣으면 이후 전류를 낮추더라도 모든 회로의 전류가 낮아질 때까지 어느 정도 시간이 요구된다. 버스의 경우도 마찬가지다. 버스에 전류의 형태로 데이터를 전송하면 해당 신호는 어느 시점까지 버스에 잔류하여 사라지지 않는다. 따라서 해당 신호들이 모두 사라질 때까지 대기하는 시간이 필요하다.
버스 이외의 요소도 존재한다. DRAM의 READ 동작은 회로를 연결했을 때 발생하는 전압 변동을 이용하여 0과 1이라는 데이터를 읽게 된다. 이때 읽은 데이터 위치의 전압 충전 상태를 다시 복구해야 메모리 상 데이터가 계속 유지되기 때문에 복구 과정에 시간을 소모한다.
위와 같은 현상들 때문에 memory cycle time 에는 memory access time 이상의 시간이 요구된다. 메모리에 엑세스 한 이후에 발생한 데이터 손실을 처리하거나 잔류 신호가 사라질 때까지 필요한 시간이 존재한다. 이 시간들은 시스템 버스와 관련된 것으로, 프로세서와는 관계가 없다.
Transfer Rate(Bandwidth)
Transfer rate은 메모리 유닛에 대해 들어오거나 나갈 수 있는 데이터의 비율을 의미한다.
Random Access Memory에 대해서는 다음의 식이 성립한다. ( 한 사이클에 한번 접근하므로, 역수는 속도 )

Non Random Access Memory 에 대해서는 다음 관계가 성립한다. ( 시간에 대한 식 )

Physical Type
| 구성 | 설명 | 예시 |
| Semiconductor memory | 반도체 기반 메모리. 기본적으로는 고가지만, 한번에 많이 생산할수록 비용이 크게 감소한다. | SRAM, DRAM, cache, 플래시 메모리 |
| Magnetic surface memory | 자기화를 이용한 메모리. 가격이 저렴하지만, 반도체 기반 메모리에 비해 속도가 많이 느리다. | 카세트테이프, 하드디스크 |
| Optical Memory | 광 레이저 기술을 이용하는 메모리 방식. 대용량이며 외부 환경의 영향을 덜 받는다. 대량 복제하여 판매하기 좋다. 단, 내용을 덮어 쓰는 것이 다른 메모리에 비해 어렵다. | CD, 블루레이 디스크 |
| Magneto-optical Memory | 데이터를 쓰는 것이 힘든 광학 메모리의 단점을 보완하기 위해 자성 재료를 이용하는 메모리. | 공 CD |
Physical Characteristics
메모리의 물리적 특성은 전류를 끊었을 때도 데이터가 영구적인지(volatile), 내용을 지울 수 있는지(erasible)를 논한다.
| 특성 | 설명 | 예시 |
| volatile | 전류가 꺼지면 모든 데이터가 사라진다. | RAM |
| nonvolatile | 전류가 꺼져도 데이터가 사라지지 않으며, 한번 내용을 기록하면 의도적으로 바꾸지 않는 한 유지된다. | 자기 기반 메모리 |
| erasible | 내용을 지우고 쓸 수 있다. | 공 CD, 하드 디스크 등 |
| nonerasible | 저장 유닛을 파괴하지 않는 한 내용이 변하지 않는다. | ROM, CD |
Organization
메모리에 대해 설명하는 organization은 워드를 구성하는 비트들의 물리적 배열을 의미한다. 이 구조를 어떻게 구성하는가에 따라 한번에 읽어올 수 있는 데이터의 단위가 달라질 수 있다.
Memory Hierarchy
메모리에 대해 가장 중요한 요소에는 용량, 속도, 비용이 있다. 가장 이상적인 경우는 용량이 많고 속도가 빠른 메모리를 싸게 사용하는 것이지만, 이들 사이에는 트레이드오프가 있다. 메모리의 속도가 빨라질수록 가격은 상승한다. 용량이 크면 가격은 싸지만 접근 속도는 느리다. 이유는 단순한데, SRAM이 DRAM보다 비싸기 때문이다. SRAM은 속도는 빠르지만 비용이 비싸기 때문에 용량을 무작정 늘릴 수 없다. 반대로 DRAM은 가격이 싸서 용량을 크게 늘릴 수 있지만 속도는 SRAM보다 많이 느리다.
따라서 하나의 메모리만 사용해서는 세가지 요소를 모두 잡을 방법이 없다. 컴퓨터는 이 문제를 해결하기 위해 메모리를 계층화하는 방향으로 진화했다.
메모리 계층은 상위 계층으로 갈수록 속도는 빠르지만 용량이 작고, 하위 계층으로 갈수록 용량은 크지만 비용은 저렴해지는 특성을 지닌다. 상위 계층에는 최근 접근한 데이터의 locality을 기반으로 근미래에 사용될 가능성이 높은 데이터들을 하위 계층에서 가져와 저장하고, CPU가 데이터를 요청하면 해당 데이터를 제공한다. CPU는 위에서 아래로 원하는 데이터를 물어보면서 데이터를 찾는다. locality에 의해 CPU가 찾는 데이터는 대부분 상위 계층에서 찾을 수 있으므로 결과적으로 고성능, 대용량, 저비용으로 메모리 시스템을 운영할 수 있게 된다.
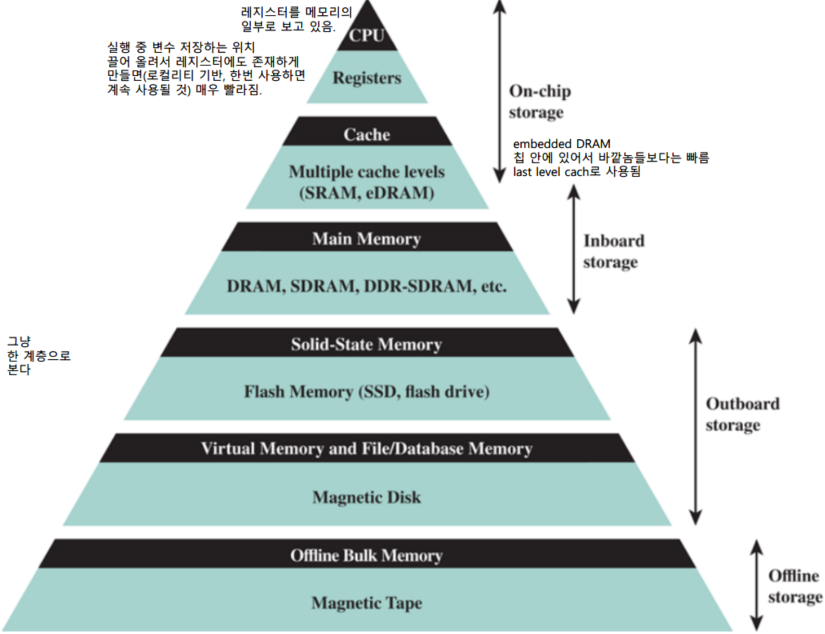
메모리 계층은 위에서 아래로 내려갈수록 제시되는 특징을 가진다.
- 가격이 싸진다.
- 접근 시간이 길어진다.
- 데이터 전송율이 느려진다.
- 크기가 커진다.
아래 계층으로 내려갈수록 성능이 떨어지므로, 전반적인 성능 향상을 위해서는 하위 계층에 대한 접근 횟수를 줄여야한다.

메모리 계층에 대한 디자인 원칙
메모리 계층을 구성할 때 고려해야 하는 점들은 다음과 같다.
- Locality: 데이터의 로컬리티가 커야 하위 계층까지 가지 않고 다음 데이터를 얻을 수 있다.
- Inclusion: 상위 계층은 하위 계층의 데이터를 복사하여 가진다.
- Coherence: 인접 메모리 계층들에 존재하는 동일 데이터는 일관성을 가져야 하며, 특정 캐시에서 데이터가 수정되면 다른 모든 계층의 데이터도 일관성 유지를 위해 값을 변경해야 한다.
컴퓨터에서 실행되는 프로그램들은 locality가 높은 것으로 알려져 있다. 따라서 컴퓨터는 현재 사용되는 데이터를 기반으로 근미래에 사용될 데이터들을 캐시에 미리 대기시켜둘 수 있다.
이때 각 계층 캐시는 자신의 하위 계층 메모리에 있는 데이터 중 더 사용될 확률이 높아 보이는 데이터를 가져다가 저장해둔다. 따라서 상위 계층의 데이터는 하위 계층에 있는 일부 데이터와 중복된다(Inclusion). 만약 상위 계층과 하위 계층이 별개의 데이터를 가지고 있다면 어떻게 될까? CPU가 데이터를 찾기 위해 최상위 캐시에 정보를 요청했다고 가정해보자. 현재 최상위 캐시는 CPU가 가지고 있는 데이터가 없어서 자신의 하위 계층에 해당 데이터가 있는지 물어본다. 하위 계층은 상위 계층과 전혀 다른 데이터를 가지고 있으므로 또 하위 계층에 데이터를 요청한다. 해당 과정이 반복되다 보면 결국 RAM에 직접 데이터를 요청하게 된다. 이 경우 메모리의 계층화는 오히려 오버헤드로 작용하게 된다. 그런데, 앞에서 언급했듯이 특정 클러스터에 있는 데이터들은 locality가 있어서 근방의 데이터를 사용할 확률이 크다. 만약 상위 계층의 내용과 하위 계층의 내용이 포함 관계에 있다면 locality에 의해 관련된 데이터를 보다 상위 계층에서 발견할 수 있을 것이다. 즉 상위 계층의 메모리와 하위 계층의 메모리가 서로 포함관계에 있어야 locality에 의한 효과를 볼 수 있다.
메모리 사이의 데이터 일관성도 중요한 문제 중 하나이다. 각 계층에는 하나 이상의 메모리가 존재하며 메모리마다 정보가 중복해서 나타난다. 이때 특정한 변수의 값이 변경되면 해당 변수를 가진 모든 메모리의 값도 변경해야 한다. 이때 데이터의 일관성의 종류는 크게 2가지로 나눌 수 있다.
| 종류 | 설명 |
| Vertical Coherence | 다른 계층 사이의 데이터 일관성. 실제 하위 계층이 사용될 때 일관성을 수정해도 된다. |
| Horizontal Coherence | 동일 계층 사이의 데이터 일관성. 동일 계층 내 특정 메모리에 저장된 값이 변경되면 다른 메모리에 있는 동일한 값들도 즉시 변경되어야 한다. |
동일 계층에서 발생한 값의 변화는 다른 메모리들에 바로 반영되어야 한다. 만약 해당 값이 바로 반영되지 않는다면 상위 계층에서 현재 계층에 데이터를 요청했을 때 어떤 메모리에게 요청했는가에 따라 다른 값을 얻기 때문이다. 반면 다른 계층 사이의 값의 변화는 즉시(realtime) 처리할 필요까지는 없다. 기본적으로 계층은 포함 관계에 있으므로 상위 계층에 있는 모든 변수는 하위 계층에 존재한다. 만약 값이 바뀔때마다 모든 하위 계층의 값을 수정하게 된다면 버스 오버헤드가 매우 심해 컴퓨터가 제대로 동작하지 못할 것이다. 따라서 하위 계층은 필요할 때 값을 바꾼다.
동일 계층 내에서 일관성을 유지하는 방법에는 두가지가 존재한다. 하나는 데이터가 수정되었을 때 각 계층에 해당 데이터를 보내주는 방식이다. 매우 친절하긴 한데, 버스 점유율이 너무 높아지기 때문에 사용하지는 않는다. 두번째는 데이터가 수정되었다는 사실만을 전달하는 방식이다. 특정 변수의 값이 변하면 해당 사실을 다른 메모리들에게 전달한다. 각 메모리들은 대응되는 변수의 값을 그냥 지워버리고, 나중에 필요할 때 찾아서 사용한다. 이 경우 버스를 점유할 필요가 없다.
Multi Level Memory Access

시간은 확률적으로 계산된다. 각 계층에서 걸리는 시간은 이전 계층에서 발견하지 못할 확률, 현재 계층에서 찾을 확률 및 현재 계층의 메모리에 대한 access time을 곱해 계산한다. 이후 해당 값을 다 더한다.

비용은 위 수식을 통해 계산된다. 하위 계층의 사이즈를 상위 계층보다 매우 크게 하는 것이 중요하다.

메모리는 저비용으로 큰 용량 및 좋은 성능을 가지는 것이 이상적이나, 실제로는 비용과 성능은 트레이드오프 관계를 가지므로 일반적인 방법으로는 메모리 성능을 크게 높일 수 없다. 따라서 컴퓨터는 메모리 측면을 locality을 근거로 계층화하여 상위 계층의 높은 성능 및 하위 계층의 큰 용량의 장점을 비교적 낮은 가격으로 해결할 수 있도록 진화했다.
'CS > 컴퓨터구조' 카테고리의 다른 글
| [컴퓨터구조] 캐시(2) (1) | 2022.10.05 |
|---|---|
| [컴퓨터구조] 캐시(1) (1) | 2022.10.03 |
| [컴퓨터구조] Interconnection (0) | 2022.09.27 |
| [컴퓨터구조] 컴퓨터의 기능 (0) | 2022.09.24 |
| [컴퓨터구조] 컴퓨터의 성능 측정 (1) | 2022.09.22 |



