생각하다 보니, 자바스크립트를 사용하면서도 실제로 이 언어가 어떻게 작동하는지에 대해서는 생각해 본 적이 없었다.
당연한 이야기지만, 컴퓨터는 프로그래밍 언어 자체를 인식하지는 못한다. 기본적으로 프로그래밍 언어는 사람의 사용을 목적으로 만들었기 때문에, 이를 기계어로 번역하는 과정이 필요하다. 이 시점에서 나는 자바스크립트의 경우 어떻게 변환과정을 거치는지에 대해 궁금해졌다.
자바스크립트에 대해
우선, 자바스크립트가 무엇인지 생각해보자. 자바스크립트는 ECMA-262의 사양을 구현하는 언어로, 비영리 표준화 단체인 ecma의 TC39 위원회에 의해 관리되고 있다. 사양은 일종의 인터페이스라고 볼 수 있는데, 사양을 구현한다는 의미는 자바스크립트가 ECMA script라는 인터페이스를 만족하도록 구현되었다는 의미로, 해당 사양을 구현하는 여러가지 프로그램에서 스크립트 언어로 작동할 수 있다고 보면 된다.
언급한대로 자바스크립트는 ECMA-262라는 사양을 만족하는 언어로, 해당 조건을 만족하는 다양한 엔진에서 사용될 수 있다. 우리가 사용하는 다양한 브라우저(크롬, 파이어폭스, 엣지 등)나, nodejs 등의 웹서버 등이 이런 엔진에 속한다. 이때, 이러한 각각의 엔진들은 동일 사양에 대해 각자의 구현방식을 생각하게 되고, 이에 따라 첨예하게 다른 구현이 발생할 수 있다. 그렇기에 사실 자바스크립트 엔진이 어떻게 작동하는가에 대한 것은 크게 의미가 없을 수도 있는데, 컴파일러 구현 방식 역시도 당연히 각각의 엔진마다 다르기 때문이다. 그렇지만, 사실 핵심은 구현이 아니라 사양이다. 사양을 만족하는 것은 동일한 동작을 보장하는 것이기 때문이다. 이런 이유로 우리는 크롬과 파이어폭스와 같은 브라우저나 nodejs 같은 웹서버를 사용하지만, 특정 코드에 대해 동일한 동작을 기대할 수 있다.
엔진들의 컴파일 과정 역시 사양만 맞다면 자유롭게 구현할 수 있다. 그렇기에 세세한 정보를 알고싶다면, 각각의 엔진에 대해 깊게 파고들어야만 한다. 여기서는 이런 세세한 차이를 설명하지는 않겠다. 대신 이런 엔진들 사이에서 나타나는 공통적인 특징에 대해 설명한다.
동적 타이핑
자바스크립트는 동적 타입을 가지는 언어이다. 우리는 특정 자료형을 이용하여 변수의 타입을 한정짓지 않는다. 동적 타이핑에 의해 자바스크립트를 사용하는 프로그래머는 프로그램 내에서 사용하는 수없이 다양한 객체들에 대해 타입을 선언할 필요가 없어지므로, 언어의 사용성 측면에서 편리하다. 심지어 우리는 객체의 프로퍼티를 추가하거나, 삭제할 수도 있는데, 정적 타이핑을 채택하는 언어의 경우 이런 과정을 거칠 때마다 또 다른 타입을 할당해야 했을 것이다. 자바스크립트가 웹 상에서 사용될 수 있었던 이유는 바로 이러한 유연성 덕분이다.
var value1 = 17; // number
var value2 = "a"; // string
var value3 = {}; // object
// 타입은 런타임에 알아서 할당된다.
var obj = {
x: 1,
y: 1
};
del obj.x; // 객체 프로퍼티 추가
obj.z = 7; // 객체 프로퍼티 삭제
// 사실, 위 과정을 거칠 때 객체의 타입은 다 다르다!
그러나, 프로그래머 입장에서 반갑게 다가오는 "동적 타이핑"이라는 것은 컴파일러 입장에서는 결코 좋지 못하다. 동적 타이핑은 타입의 평가 업무를 컴파일러에게 맡기는 것으로, 컴파일러 입장에서는 주어진 객체에 대해 알고있는 정보가 없어 컴파일 과정에서 이들을 분석하고 평가하는 과정이 추가되기 때문에, 이 과정에서 정적 타이핑 언어에 비해 시간적으로 떨어지는 모습을 쉽사리 관측 가능하다.
위의 코드를 보자. value 변수들은 현재 저 코드만으로는 타입이 없다. 프로그래머가 변수를 선언한 의도가 각각의 변수를 number, string, object 타입으로 사용하는 것이었다 하더라도 이런 정보는 코드상 어디에도 드러나지 않는다. 따라서 자바스크립트 엔진은 프로그래머의 결심과는 관계없이 내부적으로 이들을 다시 해석해야만 한다. 이때, 모든 변수들에 대해 이런 해석과정이 추가되므로, 타입을 명시하는 C, C++ 등의 언어보다는 느릴 수밖에 없다.
이러한 이유로 자바스크립트 엔진들은 조금이라도 속도를 늘리기 위해 JIT(just-in-time) 컴파일 방식을 채택한다. 현재 다양한 언어들이 JIT를 채택하고 있는데, 이는 실제 서브루틴이 "실행되는 시점" 에 Re-Compile을 진행하여 초기 컴파일 시간을 줄이는 방식으로, 상대적으로 이전에 비해 초기 실행시간이 빨라지는 효과가 있다. 이렇게 내부적으로 컴파일된 프로그램은 인터프리터에 의해 곧바로 실행되고, 컴파일과 실행이라는 두 프로세스는 서로 피드백을 주고 받는다.
개략적인 엔진의 구조
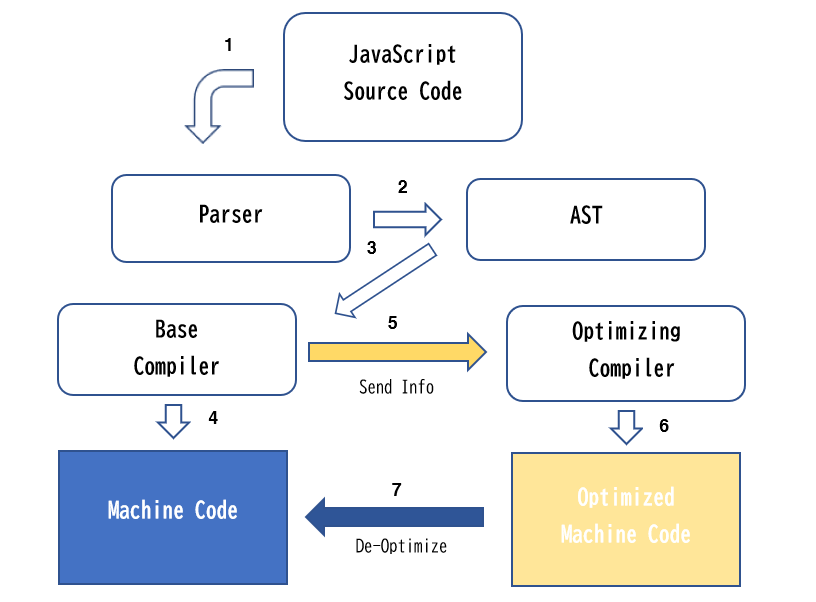
자바스크립트 엔진의 종류는 다양하다. 그렇지만 공통적으로 위와 유사한 흐름을 가진다. 흐름은 다음과 같다.
- 소스코드를 Scan 하여 토큰화한다.
- 생성된 토큰 스트림을 파싱하여 AST를 구성한다.
- 구성된 AST을 Base Compiler에 전달한다.
- 전달된 AST에 기반하여 Machine Code을 생성한다
- 프로그램을 실행할 때 생성된 정보를 Optimizing Compiler에게 전달한다.
- 전달된 정보를 기반으로 특정 hot function들을 최적화한 Optimized Machine Code을 생성한다.
- hot function에 정의되지 않은 타입이 인자로 오면, 이를 De-Optimize하여 원래 코드로 되돌린다.
현대 많은 컴파일러들은 2종류 이상의 컴파일러를 가진다. 자바스크립트 엔진 역시 다르지 않은데, 거의 모든 자바스크립트 엔진들은 통상의 컴파일 과정을 수행하는 Base Compiler 말고도 최적화 관련 컴파일을 수행하는 Optimizing Compiler을 가진다.
Optimizing Compiler은 이름에서 유추할 수 있듯 최적화와 관련된 작업을 수행한다. 그렇다면, 이들이 최적화하는 대상이 누구인가? 해당 컴파일러들은 자주 사용하는 함수에 대한 매개변수의 타입을 지정하는 방식의 함수 최적화를 수행한다. 이때 자주 사용되는 함수들은 hot function 등의 이름으로 불리게 된다.
Hot Function
function load(obj) {
return obj.x;
}
매개변수의 타입이라는 부분을 생각해보자. 위 load 함수에서 obj.x을 찾기 위해 컴파일러는 많은 시도를 수행한다.
- x는 어떤 위치(선언상의 위치)에 있는가?
- 인자로 들어온 객체가 실제로 x를 가졌는가?
- x가 혹시 프로토타입 체인에 있지는 않는가?
- 객체는 어떤 프로퍼티를 가진 타입인가?
- x의 메모리상의 위치는 어디인가?
프로그램을 실행하게 되면 위와 같은 많은 판단 끝에 해당 함수는 obj 객체의 x라는 프로퍼티 정보를 얻을 수 있다. 이때 원칙적으로 위와 같은 과정은 함수에 대한 "모든" 인자에 대해 수행될 것이므로, 당연히 속도가 떨어질 수밖에 없다. 그런데, 정말로 위와 같은 과정이 "모든" 종류의 인자에 대해서 수행될 필요가 있을까? 사실, 현실에서 사용하는 대부분의 함수의 인자는 어느정도 정형화 되어있는 경우가 많다. 예를 들어, 수학적 계산을 수행하는 함수에 string이나 object 타입의 변수가 들어갈 수도 있지만, 대부분의 상황에서는 number 타입의 변수를 인자로 전달하여 계산을 수행한다. 마찬가지로 문자열에서 특정 문자의 수를 세는 함수에 대해서 원칙적으로는 다양한 형태의 객체 및 자료형이 전달될 수 있겠지만, 정상적인 이용 방식은 문자열을 전달하는 것이다. 그렇기에, dynamic typing을 사용하고 있다 하더라도, 실제 인자 자체가 반드시 동적일 필요는 없다. 이 경우, 특정 타입의 인자에 반응하여 최적화 된 작업을 수행하는게 나을 것이다.
최적화 과정을 설명하기 이전에, 타입에 대한 설명을 먼저 할 필요가 있을 것 같다. 자바스크립트는 동적 타입이기는 하지만, 이게 타입 시스템이 없다는 것을 의미하지 않는다. 내부적으로는 각각의 엔진에서 구현한 방식에 따라 각각의 객체에 대해 일종의 히든 클래스 타입이 존재하기도 하지만, 우리가 이를 신경 쓸 필요가 없을 뿐이다. 아무튼 모종의 방법에 의해 객체의 구조를 타입으로 특정할 방법을 자니게 된다. 각각의 타입은 프로퍼티에 민감하게 작동하는데, 동일 이름의 프로퍼티라도 순서에 따라 다른 타입에 해당하며, 프로퍼티가 추가됨에 따라 새로운 타입도 추가된다.
내부적 과정에 의해 자바스크립트 엔진은 함수 인자의 타입을 알 수 있다. 해당 프로그램이 진행됨에 따라 Base Compiler은 자주 사용하는 함수(hot function)에 대하여 인자의 타입관련 정보를 얻어, 이를 Optimizing Compiler에게 보낸다. Optimizing Compiler은 해당 함수의 매개변수의 타입을 데이터를 통해 특정하도록 어셈블리/레지스터 수준에서 프로그램을 최적화한다. 이렇게 특정된 타입의 정보는 프로그램 내부에 저장되어 들어온 인자의 타입에 대한 비교대상이 되며, 최적화 된 코드를 실행할지, 아니면 De-Optimize 하여 원래 코드를 실행할지 결정하기 위한 열쇠가 된다. 최적화된 코드가 실행되는 경우, 각각의 프로퍼티 위치에 저장된 히든 클래스의 구조에 따라 바로 접근할 수 있게 된다.


이러한 타입은 최대 4개까지 지원하며, 그 이상에 대해서는 비교를 수행하지 않고 기존의 코드를 수행한다고 한다.
당연히 타입의 개수가 증가함에 따라 함수 자체의 성능은 감소하게 된다. 타입의 개수 증가는 비교 횟수의 증가로 이어지기 때문이다. 이런 이유로 함수의 인자로 올 수 있는 모든 타입을 포용하는 하나의 타입만을 사용하는 것이 최적화 과정에 있어 가장 효율적이라고 한다.
결론
자바스크립트 엔진은 JIT 컴파일, hot function optimizing, hidden class 등 다양한 방식으로 머신 코드를 최적화하여 프로그램의 속도를 향상시키고 있다. 엔진이 실행되는 도중에 컴파일러와 인터프리터는 서로 정보를 주고 받으며 프로그램을 최적화한다.
hot function에 대한 최적화는 어셈블리 레벨에서 인자로 오는 타입에 대해 정보를 저장해두고, 이를 비교하는 방식으로 작동하므로, 함수의 인자에 대해서는 최대한 고정된 타입을 사용하는 것이 성능면에서 유리하다.
어셈블리 수준의 코드는 node 등에서 파일을 실행할 때 다음과 같은 명령어를 추가하면 가능하다.
--print-opt-code
--print-bytecode
--trace-ic
--trace-opt / --trace-deopt
사용 예시 : node --print-opt-code src/index.js >> opt-code.txt
출처
주로 유튜브를 통해 정보를 얻었다.
https://www.youtube.com/watch?v=p-iiEDtpy6I&list=LL&index=3
https://www.freecodecamp.org/news/javascript-under-the-hood-v8/
'javascript > pure' 카테고리의 다른 글
| [자바스크립트] setTimeout이 정확한 시간을 보장하지 않는 이유 (0) | 2023.01.19 |
|---|---|
| [자바스크립트] RegExp - 자바스크립트와 정규표현식 (0) | 2022.02.02 |
| [자바스크립트] Promise.all / allSettled (0) | 2021.12.28 |
| [자바스크립트] [native code]의 의미 (0) | 2021.12.19 |



