mysql2
https://github.com/sidorares/node-mysql2
GitHub - sidorares/node-mysql2: fast mysqljs/mysql compatible mysql driver for node.js
:zap: fast mysqljs/mysql compatible mysql driver for node.js - GitHub - sidorares/node-mysql2: fast mysqljs/mysql compatible mysql driver for node.js
github.com
mysql2 라이브러리는 nodejs 환경에서 mysql에 접근하기 쉽도록 도와주는 라이브러리로, 기존에 별도로 존재하던 라이브러리를 대중적으로 사용되던 mysql 라이브러리와 동일한 API를 가지도록 변경하여 거의 동일한 사용감을 가진다.
공식 문서에서는 mysql 라이브러리가 제공하는 API 대한 깃허브 사이트를 리소스로 제공할 정도로 두 라이브러리가 제공하는 API는 거의 차이가 없다. 다만 해당 API들을 구현하는 실제 코드는 동일하지 않으며, 구현 상의 차이로 인해 벤치마크 결과 mysql2가 우세한 경향을 보인다고 한다.
mysql2의 장점
개인적으로 mysql2를 선택했을 때 직관적으로 와닿았던 장점은 다음과 같다.
- typescript 환경을 위한 index.d.ts 파일을 라이브러리 자체적으로 지원
- Promise API를 라이브러리 자체적으로 지원
타입스크립트를 위한 타이핑 기본 지원
mysql 라이브러리를 타입스크립트 환경에서 설치하는 경우, 다음과 같은 에러가 발생한다.
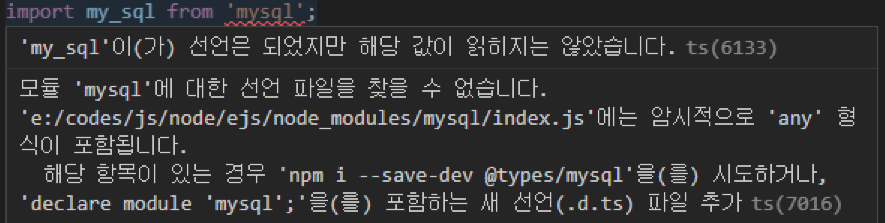
타입스크립트 환경에서 모듈을 사용하기 위해서는 해당 모듈에 대한 타입 선언이 필요하다. 그러나 mysql 라이브러리 "자체"에는 이러한 타입 선언 파일이 존재하지 않으므로, @types/mysql 모듈을 따로 설치해야 한다.

반면 mysql2는 기본적으로 타입 선언을 제공하므로 별도의 모듈을 설치할 필요가 없다.

Promise API 자체 지원
mysql 라이브러리는 기본적으로 콜백 기반으로 동작한다. 사용자가 async / await 문법 기반으로 사용하기 위해서는 해당 함수를 util.promisify 같은 래퍼 함수로 감싸 사용하는 것을 고려할 수 있겠다.
const pool = my_sql.createPool({});
//1. 콜백 방식 그대로 사용하기
pool.query("SELECT * FROM products where id = ?;",[id],(err, result, fields) => {
if(!err) {
console.log(result);
console.log(fields);
}
// mysql 라이브러리의 기본 골자.
});
//2. promisify 래퍼함수로 감싼 후 async/await 문법으로 사용하기.
const query = promisify(pool.query);
const [result, fields] = await query("SELECT * FROM products where id = ?;", [id]);다만 이 방법을 타입스크립트 환경에서 사용하기는 그리 쉽지 않다. query 함수는 3개의 오버로딩을 가지는데, promisify 래퍼 함수를 거치면 하나의 형태에 대해서만 타입 추론이 동작하기 때문이다.
구체적으로 query 함수의 오버로딩 형식은 다음과 같다.
- (query)
: 쿼리 객체를 설정한다. - (options, callback(err, result, fields))
: 쿼리 옵션(문자열 또는 객체)과 쿼리가 성공했을 때 실행할 콜백 함수를 설정한다. - (options, values, callback(err, result, fields))
: 옵션과 해당 해당 쿼리문에 삽입할 값 배열(values) 및 콜백 함수를 설정한다.
이때 query 함수를 프로미스화하기 위해 promisify을 씌우는 경우 결과로 나온 함수가 단 하나의 인자만을 인식하는 형태로 고정되어 오버로딩이 고장나는 현상이 발생하므로, 제대로 사용할 수 없게 된다.


이를 해결하기 위해서는 언급한 3가지 함수에 대한 인터페이스를 직접 선언하면 된다. 문제는 mysql 라이브러리 전체가 콜백 기반이라는 점이다. 만약 query API가 아닌 다른 API에 대해서도 async / await 문법을 쓰고 싶은 경우 앞서 언급한 "promisify을 통한 프로미스화 + 직접 타입 선언" 이라는 귀찮은 작업을 계속 반복해야 한다.
https://stackoverflow.com/questions/52691279/typescript-add-types-for-promisifed-methods
위와 같은 귀찮은 작업을 수행하고 싶지는 않지만 여전히 mysql 라이브러리를 사용하고 싶은 경우, mysql 라이브러리에 대한 프로미스 래퍼를 제공하는 별도의 라이브러리 설치를 고려할 수 있겠다.
https://www.npmjs.com/package/promise-mysql
promise-mysql
A bluebird wrapper for node-mysql. Latest version: 5.2.0, last published: 9 months ago. Start using promise-mysql in your project by running `npm i promise-mysql`. There are 245 other projects in the npm registry using promise-mysql.
www.npmjs.com
mysql 라이브러리가 프로미스 API 사용을 위해 위와 같은 귀찮고 복잡한 과정을 거쳐야 하는 반면, mysql2는 자체적으로 프로미스 래퍼를 제공하고 있다. 사용자는 'mysql2/promise' 경로를 통해 쉽게 프로미스 API을 사용할 수 있다.
import mysql from 'mysql2/promise';
export class MYSQL_DB {
// 여러 유저에 대응해야 되므로 pool로 연결
private static pool: mysql.Pool;
static init() {
this.pool = mysql.createPool({
host: KEY.DB.MYSQL.HOST,
user: KEY.DB.MYSQL.USER,
password: KEY.DB.MYSQL.PASSWORD,
database: KEY.DB.MYSQL.DB
});
}
static async query(sql: string, values?: any) {
return await this.pool.query(sql, values);
}
static async execute(sql: string, values?: any) {
return await this.pool.execute(sql, values);
}
}어떻게 보면 언급한 두 기능은 단순히 다른 라이브러리를 설치해서 해결할 수 있는 문제기는 하다. 다만 이러한 기능을 자체적으로 제공하면서 추가적인 기능도 있는 mysql2 라이브러리를 두고 mysql 라이브러리를 사용할 이유는 딱히 없다. 자바스크립트 환경에서 콜백 기반 비동기 동작을 채택하는 경우가 아니라면 mysql2가 편의성 면에서 더 좋다.
간단한 사용법
구체적인 사용법은 공식 문서를 참고하는 것이 가장 좋다. 여기서는 가장 기본적인 수준만 설명한다.
mysql DBMS 연결
import mysql from 'mysql2/promise';
// 커넥션 풀을 이용하는 경우
const pool = mysql.createPool({
host: KEY.DB.MYSQL.HOST,
user: KEY.DB.MYSQL.USER,
password: KEY.DB.MYSQL.PASSWORD,
database: KEY.DB.MYSQL.DB
});
await this.pool.query(sql, values);
// 커넥션 풀을 이용하지 않는 경우
const connection = await mysql.createConnection({});
connection.query("something...");
await connection.end();createPool에 여러 설정을 넘겨서 커넥션 풀을 얻는다. 커넥션 풀을 이용하는 경우 커넥션을 별도로 할당 및 해제할 필요가 없기 때문에 사용이 매우 쉬워지며, 코드 상의 실수로 connection.end( )을 포함하지 않아 발생하는 커넥션 자원 고갈 문제가 발생하지 않는다.
쿼리 사용법
쿼리문의 기본 골자는 다음과 같다.
const [result, fields] = await MYSQL_DB.query('SELECT * FROM products where id = ?', [id]);- 인자
- 쿼리문 | 쿼리 옵션: 쿼리를 설정한다.
- 변수 목록: ? 자리에 들어갈 변수를 배열 형태로 설정한다.
- 반환값
- result: 쿼리문에 대한 수행 결과를 반환한다. 배열일 수도 있고, 단순 결과에 대한 객체일 수도 있다.
- fields: 쿼리문에 대한 추가 정보(각 칼럼의 정보 등)를 반환한다. 없을 수도 있다.
query 함수의 오버로딩 선언은 github 문서 상에서 찾을 수 있다. 다만 오버로딩 선언이나 공식문서에서 제공하는 정보만으로는 현재 수행한 쿼리가 어떤 값을 리턴하는지 명확하게 알기 힘들기 때문에 자주 사용되는 쿼리인 SELECT, INSERT, UPDATE, DELETE에 대해 콘솔을 찍어 확인했다.
SELECT
export interface IProd {
id?: number; // auto-increment INT
title: string;
imageUrl: string;
price: number;
description: string;
}
...
private static async getProducts() {
const [arr, _] = await MYSQL_DB.query('SELECT * FROM products') as [IProd[], any];
// 데이터패킷[], 필드 패킷[] = 칼럼 정의[]
console.log(arr, _);
return arr;
}
각 행을 객체로 변환한 배열 및 선택한 열의 정의를 반환한다. ColumnDefinition의 경우 열의 이름, 인코딩 등의 정보를 담고 있다. 결과 값만을 얻고 싶다면 배열의 첫번째 요소(arr)만 가져오면 되며, 해당 요소도 배열이라는 점을 기억하자.
INSERT
// 존재하지 않는 데이터의 경우 -> INSERT
const [rows, _] = await MYSQL_DB.query(
"INSERT INTO PRODUCTS(title, imageUrl, price, description) VALUES (?, ?, ?, ?)",
[this.title, this.imageUrl, this.price, this.description]) as [ResultSetHeader, any];
console.log("insert", rows, _); // ResultSetHeader을 반환
this.id = rows.insertId;
INSERT 쿼리는 ResultSetHeader 인스턴스를 반환하며, fields는 없다. 내부에 insertId 프로퍼티가 설정되어 있어 현재 입력한 값의 id가 무엇인지 알 수 있다. 이러한 특징을 이용하면 다음과 같은 동작을 구현할 수 있다.
constructor(title: string, imageUrl: string, price: string | number, description: string, id?: number) {
this.id = id;
this.title = title;
this.imageUrl = imageUrl;
const _price = Number(price);
this.price = isNaN(_price) ? 0 : _price;
this.description = description;
}- products 테이블에 새로운 행을 추가하기 위해 PRODUCT 객체에 id를 제외한 값을 설정한다.
- save 메서드를 호출하여 INSERT 쿼리를 수행, 반환된 ResultSetHeader 인스턴스에서 insertId를 추출하여 현재 객체의 비어있는 id 값을 채운다.
UPDATE, DELETE
// UPDATE
const [result, _] = await MYSQL_DB.query(
"UPDATE PRODUCTS SET title = ?, imageUrl = ?, price = ?, description = ? WHERE id = ?;"
,[this.title, this.imageUrl, this.price, this.description, this.id]);
console.log("update", result, _); // ResultSetHeader 타입을 반환
// DELETE
const [result, _] = await MYSQL_DB.query("DELETE FROM products WHERE id = ?",[id])
as [ResultSetHeader, any];
console.log(result); //ResultSetHeader 반환UPDATE와 DELETE 모두 INSERT 쿼리처럼 ResultSetHeader을 반환하며, fields는 없다.


Query와 Execute
mysql 및 mysql2 라이브러리에는 query 말고 execute라는 함수를 이용해도 쿼리를 DBMS에 전달할 수 있다. 이때 두 함수의 차이는 쿼리문을 어디서 처리하는지에 있다.
// 존재하지 않는 데이터의 경우 -> INSERT
const [rows, _] = await MYSQL_DB.query(
"INSERT INTO PRODUCTS(title, imageUrl, price, description) VALUES (?, ?, ?, ?)",
[this.title, this.imageUrl, this.price, this.description]) as [ResultSetHeader, any];
console.log("insert", rows, _); // ResultSetHeader을 반환
this.id = rows.insertId;위 코드를 살펴보면 쿼리의 변수 부분에 ? 표시가 된 것을 볼 수 있다. mysql 및 mysql2 라이브러리는 SQL injection을 방지하기 위해 내부적으로 sqlstring 라이브러리를 이용하여 values 배열에 있는 값을 처리한다.
query의 경우 이러한 값의 처리를 sqlstring을 이용하여 클라이언트에서 수행하는 반면, execute는 mysql DBMS 수준에서 처리한다. 실제 코드에서도 이러한 모습이 드러난다. Pool 클래스가 호출하는 함수 및 객체들을 통해 알아보자.
Query의 경우
- query: 내부적으로 Connection.createQuery을 호출한다.
- createQuery: Commands.Query 객체를 반환한다.
- conn.query: Connection 객체의 query 메서드를 호출한다.
- Connection.query: 내부적으로 this.format을 호출한다.
- this.format: sqlstring.format 함수를 이용하여 처리한 문자열을 반환한다.
query는 Commands.Query를 반환하기 전에 sqlstring.format을 이용하여 내부적으로 쿼리를 미리 생성하며, Query.start 함수가 실행되면 해당 내용을 패킷으로 쓰게 된다. 결과적으로 query 함수를 이용하는 경우 완성된 쿼리 문자열을 DBMS에게 질의하므로, Query.start 내부에서 패킷을 생성할 때 호출하는 Packet.Query.toPacket의 코드가 간결하다.
Execute의 경우
- execute: Connection 객체의 execute 메서드를 호출한다.
- conn.execute: 값을 가공한 이후 Commands.Execute 객체를 생성하고 반환한다.
execute는 Commands.Execute을 반환하는 과정에서 문자열 치환 과정이 따로 존재하지 않으며, 쿼리와 함께 각 인자들을 서버에 보내 처리해야 한다. 이러한 이유로 Packet.Execute.toPacket의 코드가 상당히 길다. 서버에서는 쿼리문과 인자를 받아 prepared statement을 수행하고, 결과를 반환한다.
execute의 본질은 prepared statement을 통한 최적화 및 sql injection 방지에 있다고 한다.
query 함수는 sqlstring을 통해 자바스크립트 기준으로 구성된 객체 및 타입을 mysql DBMS에 맞게 가공해주기 때문에 오류가 잘 발생하지 않으나, execute는 해당 값들을 그냥 넘기기 때문에 오류가 자주 발생한다. github 및 stack overflow을 찾아보면 관련된 글들을 발견할 수 있다.
- https://github.com/sidorares/node-mysql2/issues/553
- https://stackoverflow.com/questions/53197922/difference-between-query-and-execute-in-mysql
쿼리문 최적화의 로망이 있긴 하지만, 아직까지는 ORM 특유의 편리함이 내 마음을 끌어 당긴다. 나중에 데이터베이스를 좀 더 공부한 후에 쿼리문을 깊게 작성해봐야겠다.
'javascript > nodejs' 카테고리의 다른 글
| [nodejs] express-session typescript와 사용하기 (0) | 2023.03.21 |
|---|---|
| [nodejs] prisma ORM 라이브러리 (0) | 2023.02.22 |
| [오늘의 삽질] web-tree-sitter 과 emscripten (0) | 2022.05.10 |
| [nodejs] __filename & __dirname / join & resolve (0) | 2022.04.05 |
| 서버가 static 파일을 보내는 방법 (0) | 2022.04.03 |


